Some of the most impressive marketing systems I’ve seen have been developed for mobile phone marketing, especially for companies that sell prepaid phones. I don’t know why: probably some combination of intense competition, easy switching when customers have no subscription, location as a clear indicator of varying needs, immediately measurable financial impact, and lack of legacy constraints in a new industry. Many of these systems have developed outside the United States, since prepaid phones have a smaller market share here than elsewhere.
Flytxt is a good example. Founded in India in 2008, its original clients were South Asian and African companies whose primary product was text messaging. The company has since expanded in all directions: it has clients in 50+ countries including South America and Europe plus a beachhead in the U.S.; its phone clients sell many more products than text; it has a smattering of clients in financial services and manufacturing; and it has corporate offices in Dubai and headquarters in the Netherlands.
The product itself is equally sprawling. Its architecture spans what I usually call the data, decision, and delivery layers, although Flytxt uses different language. The foundation (data) layer includes data ingestion from batch and real-time sources with support for structured, semi-structured and unstructured data, data preparation including deterministic identity stitching, and a Hadoop-based data store. The intelligence (decision) layer provides rules, recommendations, visualization, packaged and custom analytics, and reporting. The application (delivery) layer supports inbound and outbound campaigns, a mobile app, and an ad server for clients who want to sell ads on their own Web sites.
To be a little more precise, Flytxt’s application layer uses API connectors to send messages to actual delivery systems such as Web sites and email engines. Most enterprises prefer this approach because they have sophisticated delivery systems in place and use them for other purposes beyond marketing messaging.
And while we’re being precise: Flytxt isn’t a Customer Data Platform because it doesn’t give external systems direct access its unified customer data store. But it does provide APIs to extract reports and selected data elements and can build custom connectors as needed. So it could probably pass as a CDP for most purposes.
Given the breadth of Flytxt’s features, you might expect the individual features to be relatively shallow. Not so. The system has advanced capabilities throughout. Examples include anonymizing personally identifiable information before sharing customer data; multiple language versions attached to the one offer; rewards linked to offers; contact frequency limits by channel across all campaigns; rule- and machine learning-based recommendations; six standard predictive models plus tools to create custom models; automated control groups in outbound campaigns; real-time event-based program triggers; and a mobile app with customer support, account management, chat, personalization, and transaction capabilities. The roadmap is also impressive, including automated segment discovery and autonomous agents to find next best actions.
What particularly caught my eye was Flytxt’s ability to integrate context with offer selection. Real-time programs are connected to touchpoints such as Web site. When a customer appears, Flytxtidentifies the customer, looks up her history and segment data, and infers intent from the current behavior and context (such as location), and returns the appropriate offer for the current situation. The offer and message can be further personalized based on customer data.
This ability to tailor behaviors to the current context is critical for reacting to customer needs and taking advantage of the opportunities those needs create. It’s not unique to Flytxt but it's also not standard among customer interaction systems. Many systems could probably achieve similar outcomes by applying standard offer arbitration techniques, which generally define the available offers in a particular situation and pick the highest value offer for the current customer. But explicitly relating the choice to context strikes me as an improvement because it clarifies what marketers should consider in setting up their rules.
On the other hand, Flytxt doesn't place its programs or offers into the larger context of the customer lifecycle. This means its up to marketers to manually ensure that messages reflect consistent treatment based on the customer's lifecycle stage. Then again, few other products do this either...although I believe that will change fairly soon as the need for the lifecycle framework becomes more apparent.
Flytxt currently has more than 100 enterprise clients. Pricing is based on number of customers, revenue-gain sharing, or both. Starting price is around $300,000 per year and can reach several million dollars.
Showing posts with label campaign management. Show all posts
Showing posts with label campaign management. Show all posts
Sunday, October 29, 2017
Thursday, September 28, 2017
Customer Data Platforms Spread Their Wings

- Broader awareness of CDP. The AgilOne event was invitation-only while the London presentation was open to any conference attendee, although BlueVenn did personally invite companies it wanted to attend. Both sets of listeners were already aware of CDPs, which isn’t something I’d expect to have seen a year or two ago. Both also had a reasonable notion of what a CDP does. But they still seemed to need help distinguishing CDPs from other types of systems, so we still have plenty more work to do in educating the market.
- Use of CDPs beyond marketing. People in both cities described CDPs being bought and used throughout client organizations, sometimes after marketing was the original purchaser and sometimes as a corporate project from the start. That was always a potential but it’s delightful to hear about it actually happening. The widely a CDP is used in a company, the more value the buyer gets – and the more benefit to the company’s customers. So hooray for that.
- CDPs in vertical markets. The AgilOne audience were all retailers, not surprisingly given AgilOne’s focus and the relation of the event to Shop.org. But I heard in London about CDPs in financial services, publishing, telecommunications, and several other industries where CDP hasn’t previously been used much. More evidence of the broader awareness and the widespread need for the solution that CDP provides.
- CDP for attribution. While in London I also stopped by the office of Fospha, another CDP vendor which has just become a Sponsor of the CDP Institute. They are unusual in having a focus on multi-touch attribution, something we’ve seen in a couple other CDPs but definitely less common than campaign management or personalization. That caught my attention because I just finished an analysis of artificial intelligence in journey orchestration, in which one major conclusion was that multi-touch attribution will be a key enabling technology. That needs a blog post of its own to explain, but the basic reason is AI needs attribution (specifically, estimating the incremental value of each marketing action) as a goal to optimize against when it's comparing investments in different marketing tasks (content, media, segmentation, product, etc.)
If there's a common thread here, it's that CDPs are spreading beyond their initial buyers and applications. I’ll be presenting next week at yet another CDP-focused event, this one sponsored by BlueConic in advance of the Boston Martech Conference. Who knows what new things we'll see there?
Friday, July 14, 2017
Blueshift CDP Adds Advanced Features
I reviewed Blueshift in June 2015, when the product had been in-market for just a few months and had a handful of large clients. Since then they’ve added many new features and grown to about 50 customers. So let’s do a quick update.
Basically, the system is still what it was: a Customer Data Platform that includes predictive modeling, content creation, and multi-step campaigns. Customer data can be acquired through the vendor’s own Javascript tags, mobile SDK (new since 2015), API connectors, or file imports. Blueshift also has collection connectors for Segment, Ensighten, mParticle, and Tealium. Product data can load through file imports, a standard API, or a direct connector to DemandWare.
As before, Blueshift can ingest, store and index pretty much any data with no advance modeling, using JSON, MongoDB, Postgres, and Kafka. Users do have to tell source systems what information to send and map inputs to standard entities such as customer name, product ID, or interaction type. There is some new advanced automation, such as tying related events to a transaction ID. The system’s ability to load and expose imported data in near-real-time remains impressive.
Blueshift will stitch together customer identities using multiple identifiers and can convert anonymous to known profiles without losing any history. Profiles are automatically enhanced with product affinities and scores for purchase intent, engagement, and retention.
The system had automated predictive modeling when I first reviewed it, but has now added machine- learning-based product recommendations. In fact, it recommendations are exceptionally sophisticated. Features include a wide range of rule- and model-based recommendation methods, an option for users to create custom recommendation types, and multi-product recommendation blocks that mix recommendations based on different rules. For example, the system can first pick a primary recommendation and then recommend products related to it. To check that the system is working as expected, users can preview recommendations for specified segments or individuals.
The segment builder in Blueshift doesn’t seem to have changed much since my last review: users select data categories, elements, and values used to include or exclude segment members. The system still shows the counts for how many segment members are addressable via email, display ads, push, and SMS.
On the other hand, the campaign builder has expanded significantly. The previous form-based campaign builder has been replaced by a visual interface that allows branching sequences of events and different treatments within each event. These treatments include thumbnails of campaign creative and can be in different channels. That's special because many vendors still limit campaigns to a single channel. Campaigns can be triggered by events, run on fixed schedules, or executed once.
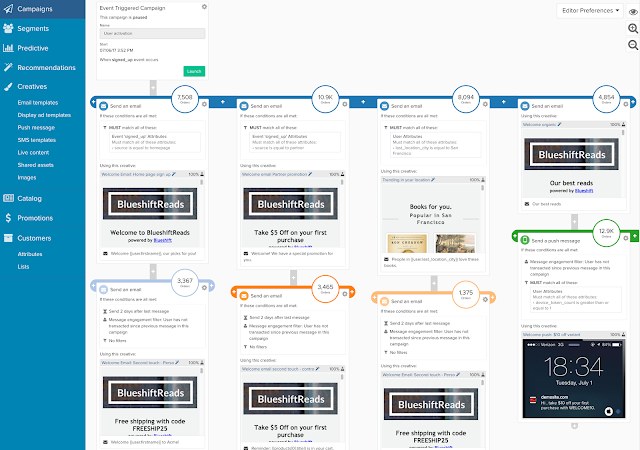
Each treatment within an event has its own selection conditions, which can incorporate any data type: previous behaviors, model scores, preferred communications channels, and so on. Customers are tested against the treatment conditions in sequence and assigned to the first treatment they match. Content builders let users create templates for email, display ads, push messages, and SMS messages. This is another relatively rare feature. Templates can include personalized offers based on predictive models or recommendations. The system can run split tests of content or recommendation methods. Attribution reports can now include custom goals, which lets users measure different campaigns against different objectives.
Blueshift still relies on external services to deliver the messages it creates. It has integrations with SendGrid, Sparkpost, and Cheetahmail for email and Twilio and Gupshup for SMS. Other channels can be fed through list extracts or custom API connectors.
Blueshift still offers its product in three different versions: email-only, cross-channel and predictive. Pricing has increased since 2015, and now starts at $2,000 per month for the email edition version, $4,000 per month for the cross-channel edition and $10,000 per month for the predictive edition. Actual fees depend on the number of active customers, with the lowest tier starting at 500,000 active users per month. The company now has several enterprise-scale clients including LendingTree, Udacity, and Paypal.
Basically, the system is still what it was: a Customer Data Platform that includes predictive modeling, content creation, and multi-step campaigns. Customer data can be acquired through the vendor’s own Javascript tags, mobile SDK (new since 2015), API connectors, or file imports. Blueshift also has collection connectors for Segment, Ensighten, mParticle, and Tealium. Product data can load through file imports, a standard API, or a direct connector to DemandWare.
As before, Blueshift can ingest, store and index pretty much any data with no advance modeling, using JSON, MongoDB, Postgres, and Kafka. Users do have to tell source systems what information to send and map inputs to standard entities such as customer name, product ID, or interaction type. There is some new advanced automation, such as tying related events to a transaction ID. The system’s ability to load and expose imported data in near-real-time remains impressive.
Blueshift will stitch together customer identities using multiple identifiers and can convert anonymous to known profiles without losing any history. Profiles are automatically enhanced with product affinities and scores for purchase intent, engagement, and retention.
The system had automated predictive modeling when I first reviewed it, but has now added machine- learning-based product recommendations. In fact, it recommendations are exceptionally sophisticated. Features include a wide range of rule- and model-based recommendation methods, an option for users to create custom recommendation types, and multi-product recommendation blocks that mix recommendations based on different rules. For example, the system can first pick a primary recommendation and then recommend products related to it. To check that the system is working as expected, users can preview recommendations for specified segments or individuals.
The segment builder in Blueshift doesn’t seem to have changed much since my last review: users select data categories, elements, and values used to include or exclude segment members. The system still shows the counts for how many segment members are addressable via email, display ads, push, and SMS.
On the other hand, the campaign builder has expanded significantly. The previous form-based campaign builder has been replaced by a visual interface that allows branching sequences of events and different treatments within each event. These treatments include thumbnails of campaign creative and can be in different channels. That's special because many vendors still limit campaigns to a single channel. Campaigns can be triggered by events, run on fixed schedules, or executed once.

Each treatment within an event has its own selection conditions, which can incorporate any data type: previous behaviors, model scores, preferred communications channels, and so on. Customers are tested against the treatment conditions in sequence and assigned to the first treatment they match. Content builders let users create templates for email, display ads, push messages, and SMS messages. This is another relatively rare feature. Templates can include personalized offers based on predictive models or recommendations. The system can run split tests of content or recommendation methods. Attribution reports can now include custom goals, which lets users measure different campaigns against different objectives.
Blueshift still relies on external services to deliver the messages it creates. It has integrations with SendGrid, Sparkpost, and Cheetahmail for email and Twilio and Gupshup for SMS. Other channels can be fed through list extracts or custom API connectors.
Blueshift still offers its product in three different versions: email-only, cross-channel and predictive. Pricing has increased since 2015, and now starts at $2,000 per month for the email edition version, $4,000 per month for the cross-channel edition and $10,000 per month for the predictive edition. Actual fees depend on the number of active customers, with the lowest tier starting at 500,000 active users per month. The company now has several enterprise-scale clients including LendingTree, Udacity, and Paypal.
Wednesday, May 24, 2017
Coherent Path Auto-Optimizes Promotions for Long Term Value
One of the grand challenges facing marketing technology today is having a computer find the best messages to send each customer over time, instead of making marketers schedule the messages in advance. One roadblock has been that automated design requires predicting the long-term impact of each message: just selecting the message with the highest immediate value can reduce future income. This clearly requires optimizing against a metric like lifetime value. But that's really hard to predict.
Coherent Path offers what may be a solution. Using advanced math that I won’t pretend to understand*, they identify offers that lead customers towards higher long-term values. In concrete terms, this often means cross-selling into product categories the customer hasn’t yet purchased. While this isn’t a new tactic, Coherent Path improves it by identifying intermediary products (on the "path" to the target) that the customer is most likely to buy now. It can also optimize other variables such as the time between messages, price discounts, and the balance between long- and short-term results
Coherent Path clients usually start by optimizing their email programs, which offer a good mix of high volume and easy measurability. The approach is to define a promotion calendar, pick product themes for each promotion, and then select the best offers within each theme for each customer. “Themes” are important because they’re what Coherent Path calculates different customers might be interested in. The system relies on marketers to tell it what themes are associated with each product and message (that is, the system has no semantic analytics to do that automatically). But because Coherent Path can predict which customers might buy in which themes, it can suggest themes to include in future promotions.
Lest this seem like the blackest of magic, rest assured that Coherent Path bases its decisions on data. It starts with about two years’ of interactions for most clients, so it can see good sample of customers who have already completed a journey to high value status. Clients need at least several hundred products and preferably thousands. These products need to be grouped into categories so the system can find common patterns among the customer paths. Coherent Path automatically runs tests within promotions to further refine its ability to predict customer behaviors. Most clients also set aside a control group to compare Coherent Path results against customers managed outside the system. Coherent Path reports results such as 22% increase in email revenue and 10:1 return on investment – although of course your mileage may vary.
The system can manage other channels than email. Coherent Path says most of its clients move on to display ads, which are also relatively easy to target and measure. Web site offers usually come next.
Coherent Path was founded in 2012 and has been offering its current product for more than two years. Clients are mostly mid-size and large retailers, including Neiman Marcus, L.L. Bean, and Staples. Pricing starts around $10,000 per month.
_________________________________________________________________________
* Download their marketing explanation here or read an academic discussion here.
Coherent Path offers what may be a solution. Using advanced math that I won’t pretend to understand*, they identify offers that lead customers towards higher long-term values. In concrete terms, this often means cross-selling into product categories the customer hasn’t yet purchased. While this isn’t a new tactic, Coherent Path improves it by identifying intermediary products (on the "path" to the target) that the customer is most likely to buy now. It can also optimize other variables such as the time between messages, price discounts, and the balance between long- and short-term results
Coherent Path clients usually start by optimizing their email programs, which offer a good mix of high volume and easy measurability. The approach is to define a promotion calendar, pick product themes for each promotion, and then select the best offers within each theme for each customer. “Themes” are important because they’re what Coherent Path calculates different customers might be interested in. The system relies on marketers to tell it what themes are associated with each product and message (that is, the system has no semantic analytics to do that automatically). But because Coherent Path can predict which customers might buy in which themes, it can suggest themes to include in future promotions.
Lest this seem like the blackest of magic, rest assured that Coherent Path bases its decisions on data. It starts with about two years’ of interactions for most clients, so it can see good sample of customers who have already completed a journey to high value status. Clients need at least several hundred products and preferably thousands. These products need to be grouped into categories so the system can find common patterns among the customer paths. Coherent Path automatically runs tests within promotions to further refine its ability to predict customer behaviors. Most clients also set aside a control group to compare Coherent Path results against customers managed outside the system. Coherent Path reports results such as 22% increase in email revenue and 10:1 return on investment – although of course your mileage may vary.
The system can manage other channels than email. Coherent Path says most of its clients move on to display ads, which are also relatively easy to target and measure. Web site offers usually come next.
Coherent Path was founded in 2012 and has been offering its current product for more than two years. Clients are mostly mid-size and large retailers, including Neiman Marcus, L.L. Bean, and Staples. Pricing starts around $10,000 per month.
_________________________________________________________________________
* Download their marketing explanation here or read an academic discussion here.
Tuesday, March 14, 2017
CrossEngage Orchestrates Customer Journeys Using Events
It feels like forever since I first wrote about Journey Orchestration Engines (JOEs), although it is just one year. Orchestration was already a hot term when I started, so I take neither credit nor blame for its continued popularity. I will say that I’ve now seen enough orchestration systems to start making subtle distinctions among them.
Subtle distinctions are needed because the systems are basically similar. They all ingest data from multiple sources; convert it into unified customer profiles; apply rules and analytics to find the best message for each customer in each situation; and, send those messages to external systems for delivery. Unified customer profiles make these products look like Customer Data Platforms. JOEs that expose their profiles for external access really are CDPs; JOEs that keep the profiles for their own use, are not. In theory, a JOE could connect to an external customer database rather than building its own, but I haven’t seen that configuration in practice.
The main ways that JOEs differ include:
CrossEngage treats most data as either a customer attribute or event, using big data technologies that store inputs and to allow data access with minimal schema design. The system also stores some information that’s neither attribute nor event, such as products and locations. The vendor maps new sources into the system and can define logic to create custom events. (A self-service event builder is planned by July.) Customer data from different sources is stitched together using deterministic matching only (that is, CrossEngage will only connect different identifiers to the same person if an external source provides the relationship).
A dashboard lets users see Web site events as they stream into the system. Users can apply filters to see only certain events. Campaigns also make heavy use of events, referencing them as entry and exclusion conditions, in combination with user-defined segments; as campaign goals (which may be one or several events); and, as campaign steps (each step being a different event). Event definitions can reference other events and can include brain-bending logic such as checking whether a second train fare request specified the same departure city as the first request and happened within ten minutes. In that example, the first request would be first event in the campaign. This is tremendously powerful and, as the vendor points out with some understatement, poses a substantial technical challenge to do in real time.
Each event in a campaign can be assigned a message, which will be delivered by an external system such as an email vendor. CrossEngage can map its data to delivery systems so they can use the data in their own message templates. Alternatively, messages can be created in CrossEngage’s own templates, which can include conditional scripts for dynamic content generation. The system has external integrations for email, direct mail, mobile push, text messages, and Facebook Customer Audiences, with more on the way. It has its own connectors for Web site and Web browser messages, Web hooks, and file extracts. Users can also attach discount coupons to messages.
Campaigns can be assigned frequency caps that limit the number of messages each person receives in different time periods (per minute, per hour, per day, per week, or per month). Caps are defined separately for each campaign. Another set of caps applies across all campaigns on a per channel basis. Campaigns that generate transactional messages can be exempted from the frequency caps to ensure their messages are always sent. People can also be excluded from campaigns based on whether they were recently in that same campaign or a different one.
CrossEngage also has user journeys, which involve a set of related events. Journeys can exist within a campaign or be used outside a campaign to analyze customer behavior. If you’re keeping track, this is a different use of the term “journey” from the one I described earlier.

This is a pretty mature set of features, especially for such a young system. But nuances also include noticing what CrossEngage doesn’t do. There is no machine learning to recommend the right campaign, right message, or right message timing, although the system does support a/b tests. There’s also no visual flow chart to lay out campaigns. This is a choice made by CrossEngage based on its designers’ previous experience that flow charts quickly become too complicated to be understood or maintained over time.
Speaking of nuance, CrossEngage also has a mature approach to user rights management, allowing administrators to specify which users can perform which actions on each object. Team-based rights are on the roadmap.
CrossEngage currently has about fifteen major clients, spread across travel, ecommerce, fashion, dataing, and other industries. Pricing is based on the number of events tracked in the system, not the number of messages sent. It starts as low as $2,500 per month although average client pays about twice that.
Subtle distinctions are needed because the systems are basically similar. They all ingest data from multiple sources; convert it into unified customer profiles; apply rules and analytics to find the best message for each customer in each situation; and, send those messages to external systems for delivery. Unified customer profiles make these products look like Customer Data Platforms. JOEs that expose their profiles for external access really are CDPs; JOEs that keep the profiles for their own use, are not. In theory, a JOE could connect to an external customer database rather than building its own, but I haven’t seen that configuration in practice.
The main ways that JOEs differ include:
- Channel scope. Some systems are largely limited to online interactions, while others are built to combine online and offline channels. Some systems that look like JOEs work with only Web or email. But orchestration pretty much implies multiple channels so I’d probably exclude those from the JOE tribe.
- Decision methods. JOEs can work with conventional, rule-driven campaign structures or use automated techniques to customize the path followed by each customer. There’s also considerable variation in exactly what gets automated: some automate campaign assignments but use static content; some automatically run a/b tests and pick the winners; some automatically create customer segments that receive different content; some use machine learning to dynamically generate custom content.
- Journey framework. My original definition of JOE was quite rigorous: journey orchestration meant all campaigns were defined relative to a master model of the customer journey. This really means that stages in the journey are “states” that customers flow between, and campaigns are chosen in part based on each customer’s current state. I still think of JOEs that way and definitely see some systems organized along those lines. But when you start looking at some of the more automated decision methods, it’s harder to apply concepts of fixed states or journey flows. So I still check whether a system has a journey framework but don’t necessarily require a JOE to use it. I realize this means you could have a journey orchestration system without journeys. If that’s the silliest thing you’ve been asked to accept recently, you haven’t been watching the news.
CrossEngage treats most data as either a customer attribute or event, using big data technologies that store inputs and to allow data access with minimal schema design. The system also stores some information that’s neither attribute nor event, such as products and locations. The vendor maps new sources into the system and can define logic to create custom events. (A self-service event builder is planned by July.) Customer data from different sources is stitched together using deterministic matching only (that is, CrossEngage will only connect different identifiers to the same person if an external source provides the relationship).
A dashboard lets users see Web site events as they stream into the system. Users can apply filters to see only certain events. Campaigns also make heavy use of events, referencing them as entry and exclusion conditions, in combination with user-defined segments; as campaign goals (which may be one or several events); and, as campaign steps (each step being a different event). Event definitions can reference other events and can include brain-bending logic such as checking whether a second train fare request specified the same departure city as the first request and happened within ten minutes. In that example, the first request would be first event in the campaign. This is tremendously powerful and, as the vendor points out with some understatement, poses a substantial technical challenge to do in real time.
Each event in a campaign can be assigned a message, which will be delivered by an external system such as an email vendor. CrossEngage can map its data to delivery systems so they can use the data in their own message templates. Alternatively, messages can be created in CrossEngage’s own templates, which can include conditional scripts for dynamic content generation. The system has external integrations for email, direct mail, mobile push, text messages, and Facebook Customer Audiences, with more on the way. It has its own connectors for Web site and Web browser messages, Web hooks, and file extracts. Users can also attach discount coupons to messages.
Campaigns can be assigned frequency caps that limit the number of messages each person receives in different time periods (per minute, per hour, per day, per week, or per month). Caps are defined separately for each campaign. Another set of caps applies across all campaigns on a per channel basis. Campaigns that generate transactional messages can be exempted from the frequency caps to ensure their messages are always sent. People can also be excluded from campaigns based on whether they were recently in that same campaign or a different one.
CrossEngage also has user journeys, which involve a set of related events. Journeys can exist within a campaign or be used outside a campaign to analyze customer behavior. If you’re keeping track, this is a different use of the term “journey” from the one I described earlier.
This is a pretty mature set of features, especially for such a young system. But nuances also include noticing what CrossEngage doesn’t do. There is no machine learning to recommend the right campaign, right message, or right message timing, although the system does support a/b tests. There’s also no visual flow chart to lay out campaigns. This is a choice made by CrossEngage based on its designers’ previous experience that flow charts quickly become too complicated to be understood or maintained over time.
Speaking of nuance, CrossEngage also has a mature approach to user rights management, allowing administrators to specify which users can perform which actions on each object. Team-based rights are on the roadmap.
CrossEngage currently has about fifteen major clients, spread across travel, ecommerce, fashion, dataing, and other industries. Pricing is based on the number of events tracked in the system, not the number of messages sent. It starts as low as $2,500 per month although average client pays about twice that.
Wednesday, December 14, 2016
BlueVenn Bundles Omnichannel Journey Management, Personalization, and Single Customer View
BlueVenn has only been active in the U.S. market only since March 2016, although many U.S. marketers will recall its previous incarnation as SmartFocus.* The company offers what it calls an omnichannel marketing platform that builds a unified customer database, manages marketing campaigns, and generates personalized Web and email messages.
The unified database process, a.k.a. single customer view, has rich functionality to load data from multiple sources and do standardization, validation, enhancement, hygiene, matching, deduplication, governance and auditing. These were standard functions for traditional marketing databases, which needed them to match direct mail names and addresses, but are not always found in modern customer data platforms. BlueVenn also supports current identity linking techniques such as storing associations among cookies, email addresses, form submits, and devices. This sort of identity resolution is a batch process that runs overnight. The system can also look up information about a specific customer in real time if an ID is provided. This lets BlueVenn support real time interactions in Web and call center channels.
Users can enhance imported data by defining derived elements with functions similar to Excel formulas. These let non-technical users put data into formats they need without the help of technical staff. Derived fields can be used in queries and reports, embedded in other derived fields, and shared among users. To avoid nasty accidents, BlueVenn blocks changes in a field definition if the field is used elsewhere. Data can be read by Tableau and other third-party tools for analysis and reporting.
BlueVenn offers several options for defining customer segments, including cross tabs, geographic map overlays, and flow charts that merge and split different groups. But BlueVenn's signature selection tool has always the Venn diagram (intersecting circles). This is made possible by a columnar database engine that is extremely fast at finding records with shared data elements. Clients could also use other databases including SQL Server, Amazon Redshift (also columnar), or MongoDB, although BlueVenn says nearly all its clients use the BlueVenn engine for its combination of high speed and low cost.
Customer journeys - formerly known as campaigns - are set up by connecting icons on a flow chart. The flow can be split based on yes/no critiera, field values, query results, or random groups. Records in each branch can be sent a communication, assigned to seed lists or control groups, deduplicated, tagged, held for a wait period or until they respond, merged with other branches, or exit the flow. The “merge” feature is especially important because it allows journeys to cycle indefinitely rather than ending after a sequence of steps. Merge also simplifies journey design since paths can be reunified after a split. Even today, most campaign flow charts don’t do merges.
Tagging is also important because it lets marketers flag customers based on a combination of behaviors and data attributes. Tags can be used to control subsequent flow steps. Because tags are attached to the customer record, they can be used to coordinate journeys: one application cited by BlueVenn is to tag customers for future messages in multiple journeys and then periodically compare the tags to decide which message should actually be delivered.
Communications are handled by something called BlueRelevance. This puts a line of code on client Web sites to gather click stream data, manage first party cookies, and deliver personalized messages. The messages can include different forms of dynamic content including recommendations, coupons, and banners. In addition to Web pages, BlueVenn can send batch and triggered emails, text messages, file transfers, and direct messages in Twitter and Facebook. Next year it will add display ad audiences and Facebook Custom Audiences. The vendor is also integrating with the R statistical system for predictive models and scoring. BlueVenn has 23 API integrations with delivery systems such as specific email providers and builds new integrations as clients need them.
All BlueVenn features are delivered as part of a single package. Pricing is based on the number of sources and contacts, starting at $3,000 per month for two sources and 100,000 contacts. There is a separate fee for setting up the unified database, which can range from $50,000 to $300,000 or more depending on complexity. Clients can purchase the configured database management system if they want to run it for themselves. The company also offers a Software-as-a-Service version or hybrid system that is managed by BlueVenn on the client's own computers. BluyeVenn has about 400 total clients of which about two dozen run the latest version of its system. It sells primarily to mid-size companies, which it defines as $25 million to $1 billion in revenue.
_____________________________________________________________________________
*The original SmartFocus was purchased in 2011 by Emailvision, which changed its own name to SmartFocus in 2013 and then sold the business (technology, clients, etc.) but kept the name for itself. If you’re really into trivia, SmartFocus began life in 1995 as Brann Viper, and BlueVenn is part of Blue Group Inc. which also owns a database marketing services agency called Blue Sheep. The good news is: this won't be on the final.
 |
| The Venn in BlueVenn |
The unified database process, a.k.a. single customer view, has rich functionality to load data from multiple sources and do standardization, validation, enhancement, hygiene, matching, deduplication, governance and auditing. These were standard functions for traditional marketing databases, which needed them to match direct mail names and addresses, but are not always found in modern customer data platforms. BlueVenn also supports current identity linking techniques such as storing associations among cookies, email addresses, form submits, and devices. This sort of identity resolution is a batch process that runs overnight. The system can also look up information about a specific customer in real time if an ID is provided. This lets BlueVenn support real time interactions in Web and call center channels.
Users can enhance imported data by defining derived elements with functions similar to Excel formulas. These let non-technical users put data into formats they need without the help of technical staff. Derived fields can be used in queries and reports, embedded in other derived fields, and shared among users. To avoid nasty accidents, BlueVenn blocks changes in a field definition if the field is used elsewhere. Data can be read by Tableau and other third-party tools for analysis and reporting.
BlueVenn offers several options for defining customer segments, including cross tabs, geographic map overlays, and flow charts that merge and split different groups. But BlueVenn's signature selection tool has always the Venn diagram (intersecting circles). This is made possible by a columnar database engine that is extremely fast at finding records with shared data elements. Clients could also use other databases including SQL Server, Amazon Redshift (also columnar), or MongoDB, although BlueVenn says nearly all its clients use the BlueVenn engine for its combination of high speed and low cost.
Customer journeys - formerly known as campaigns - are set up by connecting icons on a flow chart. The flow can be split based on yes/no critiera, field values, query results, or random groups. Records in each branch can be sent a communication, assigned to seed lists or control groups, deduplicated, tagged, held for a wait period or until they respond, merged with other branches, or exit the flow. The “merge” feature is especially important because it allows journeys to cycle indefinitely rather than ending after a sequence of steps. Merge also simplifies journey design since paths can be reunified after a split. Even today, most campaign flow charts don’t do merges.
 |
| BlueVenn Journey Flow |
Tagging is also important because it lets marketers flag customers based on a combination of behaviors and data attributes. Tags can be used to control subsequent flow steps. Because tags are attached to the customer record, they can be used to coordinate journeys: one application cited by BlueVenn is to tag customers for future messages in multiple journeys and then periodically compare the tags to decide which message should actually be delivered.
Communications are handled by something called BlueRelevance. This puts a line of code on client Web sites to gather click stream data, manage first party cookies, and deliver personalized messages. The messages can include different forms of dynamic content including recommendations, coupons, and banners. In addition to Web pages, BlueVenn can send batch and triggered emails, text messages, file transfers, and direct messages in Twitter and Facebook. Next year it will add display ad audiences and Facebook Custom Audiences. The vendor is also integrating with the R statistical system for predictive models and scoring. BlueVenn has 23 API integrations with delivery systems such as specific email providers and builds new integrations as clients need them.
All BlueVenn features are delivered as part of a single package. Pricing is based on the number of sources and contacts, starting at $3,000 per month for two sources and 100,000 contacts. There is a separate fee for setting up the unified database, which can range from $50,000 to $300,000 or more depending on complexity. Clients can purchase the configured database management system if they want to run it for themselves. The company also offers a Software-as-a-Service version or hybrid system that is managed by BlueVenn on the client's own computers. BluyeVenn has about 400 total clients of which about two dozen run the latest version of its system. It sells primarily to mid-size companies, which it defines as $25 million to $1 billion in revenue.
_____________________________________________________________________________
*The original SmartFocus was purchased in 2011 by Emailvision, which changed its own name to SmartFocus in 2013 and then sold the business (technology, clients, etc.) but kept the name for itself. If you’re really into trivia, SmartFocus began life in 1995 as Brann Viper, and BlueVenn is part of Blue Group Inc. which also owns a database marketing services agency called Blue Sheep. The good news is: this won't be on the final.
Thursday, August 25, 2016
ABM Vendor Guide: State-Based Flows to Orchestrate Account Treatments
Next up in this series on ABM sub-functions described in the Raab Guide to ABM Vendors: State-Based Flows.
Your first reaction that may well be, What the heck is a State-Based Flow? That's no accident. I chose an unfamiliar term because I didn’t want people to assume it meant something it doesn’t. The Guide states:
Vendors in this category can automatically send different messages to the same contact in response to behaviors or data changes. Messages often relate to buying stages but may also reflect interests or job function. Messages may also be tied to a specific situation such as a flurry of Web site visits or a lack of contacts at a target account. Flows may also trigger actions other than messages, such as alerting a sales person. Actions are generally completed through a separate execution system. Movement may mean reaching different steps in a single campaign or entering a different campaign. Either approach can be effective. What really matters is that movement occurs automatically and that messages change as a result.
In other words, the essence of state-based flows is the system defines a set of conditions (i.e. states) that accounts or contacts can be in, tracks them as they move from one condition to the next, and sends different messages for each condition. This is roughly similar to campaign management except that campaign entry rules are usually defined independently, so customers don’t automatically flow from campaign to campaign in the way that they flow from state to state. (Another way to look at it: customers can be in several campaigns at once but only in one customer state at a time.) Customers in multi-step campaigns do move from one stage to the next, but they usually progress in only one direction, whereas people can move in and out of the same state multiple times. Journey orchestration engines manage a type of state-based flow, but they build the flow on a customer journey framework, which is an additional condition I’m not imposing here.
This may be more hair-splitting than necessary. My goal in defining this sub-function was mostly to distinguish systems where users manually assign people to messages (meaning that the messages won’t change unless the user reassigns them) from systems that automatically adjust the messages based on behaviors or new data. This adjustment is the very heart of managing relationships, or what I usually call the decision layer in my data / decision / delivery model.
Speaking of hair-splitting, you may notice that I’m being a little inconsistent in referring to message recipients as accounts, customers, contacts, individuals, or people. A true ABM system works at the account level but messages may be delivered to accounts (IP-based ad targeting), known individuals (email), or anonymous individuals (cookie- or device-based targeting, although sometimes these are associated with known individuals). Because of this, different systems work at different levels. The ideal is for message selection to consider both the state of the account and the state of the individual within the account.
As with the Customized Message category I described yesterday, vendors who qualify for State-Based Flows fall into two broad groups: those whose primary function is cross-channel message orchestration (Engagio, MRP, YesPath, ZenIQ, Mintigo*) and those that do flow management to support delivery of messages in a single channel (Evergage, GetSmartContent, Kwanzoo, Terminus, Triblio). Marketers who are looking for a primary tool to manage account relationships will be most interested in the first group.
Differentiators to consider with this group include:
______________________________________________________________________
* via its Predictive Campaign integration with Eloqua
|
ABM Process
|
System Function
|
Sub-Function
|
Number of
Vendors
|
|
Identify Target Accounts
|
Assemble Data
|
External Data
|
28
|
|
Select
Targets
|
Target
Scoring
|
15
|
|
|
Plan Interactions
|
Assemble Messages
|
Customized Messages
|
6
|
|
Select Messages
|
State-Based Flows
|
10
|
|
|
Execute Interactions
|
Deliver Messages
|
Execution
|
19
|
|
Analyze Results
|
Reporting
|
Result Analysis
|
16
|
Your first reaction that may well be, What the heck is a State-Based Flow? That's no accident. I chose an unfamiliar term because I didn’t want people to assume it meant something it doesn’t. The Guide states:
Vendors in this category can automatically send different messages to the same contact in response to behaviors or data changes. Messages often relate to buying stages but may also reflect interests or job function. Messages may also be tied to a specific situation such as a flurry of Web site visits or a lack of contacts at a target account. Flows may also trigger actions other than messages, such as alerting a sales person. Actions are generally completed through a separate execution system. Movement may mean reaching different steps in a single campaign or entering a different campaign. Either approach can be effective. What really matters is that movement occurs automatically and that messages change as a result.
In other words, the essence of state-based flows is the system defines a set of conditions (i.e. states) that accounts or contacts can be in, tracks them as they move from one condition to the next, and sends different messages for each condition. This is roughly similar to campaign management except that campaign entry rules are usually defined independently, so customers don’t automatically flow from campaign to campaign in the way that they flow from state to state. (Another way to look at it: customers can be in several campaigns at once but only in one customer state at a time.) Customers in multi-step campaigns do move from one stage to the next, but they usually progress in only one direction, whereas people can move in and out of the same state multiple times. Journey orchestration engines manage a type of state-based flow, but they build the flow on a customer journey framework, which is an additional condition I’m not imposing here.
This may be more hair-splitting than necessary. My goal in defining this sub-function was mostly to distinguish systems where users manually assign people to messages (meaning that the messages won’t change unless the user reassigns them) from systems that automatically adjust the messages based on behaviors or new data. This adjustment is the very heart of managing relationships, or what I usually call the decision layer in my data / decision / delivery model.
Speaking of hair-splitting, you may notice that I’m being a little inconsistent in referring to message recipients as accounts, customers, contacts, individuals, or people. A true ABM system works at the account level but messages may be delivered to accounts (IP-based ad targeting), known individuals (email), or anonymous individuals (cookie- or device-based targeting, although sometimes these are associated with known individuals). Because of this, different systems work at different levels. The ideal is for message selection to consider both the state of the account and the state of the individual within the account.
As with the Customized Message category I described yesterday, vendors who qualify for State-Based Flows fall into two broad groups: those whose primary function is cross-channel message orchestration (Engagio, MRP, YesPath, ZenIQ, Mintigo*) and those that do flow management to support delivery of messages in a single channel (Evergage, GetSmartContent, Kwanzoo, Terminus, Triblio). Marketers who are looking for a primary tool to manage account relationships will be most interested in the first group.
Differentiators to consider with this group include:
- orchestrates activities at account level (doesn't treat each lead independently)
- assigns Web site visitors to segments during each visit using current data
- automated models to classify content, define segments, and select best content per segment
- automated models to assign contacts to personas and select best content per persona
- automated models to recommend best actions per account
- present sets of content in sequence or all at once
- continue same experience over time across different channels
- prioritization to ensure highest value message is always presented
- accounts can be in multiple programs simultaneously
- contacts can be limited to one program at a time
- limit number of messages sent to each contact within a specified time period
______________________________________________________________________
* via its Predictive Campaign integration with Eloqua
Friday, July 01, 2016
YesPath Takes Its Own Route to Managing ABM Journeys
Account based marketing is clearly an important technique for B2B marketers, but I don’t see it displacing all other approaches. For exactly that reason, I also don’t see specialized ABM systems replacing the core marketing databases and decision engines that coordinate all marketing efforts. Today, the core roles are most often filled by marketing automation, although there are emerging alternatives such as Customer Data Platforms and Journey Orchestration Engines. Most of these tools will eventually add ABM features if they don’t have them already.
But marketers whose current tools don’t support ABM will need to something new if they want to participate in the ABM gold rush. This gives ABM database and orchestration specialists an opportunity to sell to clients who would otherwise be uninterested in new core systems. The long term, though often unstated, goal of most ABM specialists is to replace the incumbents as their clients’ primary marketing platforms.* But before they can do that, they need to get their foot in the door by making ABM easier than it would be with clients’ existing tools.
The main function provided by ABM specialists is account-level data aggregation. This in turn makes possible account-level analytics and orchestration. But data and analytics don’t create revenue by themselves, so vendors naturally stress their orchestration features. Hence “plays” from Engagio (discussed here ) and “recipes” in ZenIQ (discussed here). It’s important to recognize that both those systems also build an account-oriented database and provide ABM analytics. They are also similar in relying primarily on external systems to deliver the messages they select. This is a primary difference from conventional marketing automation products, which deliver email and often other types of messages directly. (Special bonus: by relying on marketing automation to deliver their messages, the ABM orchestrators also show that they don’t intend to replace existing marketing automation systems, removing one objection to their purchase. What they don’t say is they are diminishing the role of marketing automation from the central marketing platform to a simple delivery system, clearing the way for the ABM vendors to eventually take over the central role. But don’t tell anyone I told you.)
YesPath is another ABM orchestrator (ABMO?). It too builds an account-oriented database, provides ABM analytics, and selects messages to be delivered by other systems. Of course, every system is unique. Here are some important details that distinguish YesPath:
- focus on unknown prospects. YesPath relies heavily on Bombora intent data to find companies and individuals (or, more precisely, anonymous cookies) that are interested in topics relevant to a marketer’s products. This lets YesPath programs (which are rather unimaginatively called “programs”) determine which companies on the client’s target list are in active buying cycles, even before they have visited the company Web site or responded to an outbound promotion. YesPath can then reach those companies and individuals through a just-announced integration with the Madison Logic display ad network.
- persona-based programs. Marketers set up YesPath programs by uploading a list of target accounts and then defining the selection criteria for individuals to enter the program. These criteria can be considered a persona definition because they identify a set of similar individuals: in this sense, each program relates to a single persona. To create the selection criteria, users select a target audience of people who have shown interest in one or more topics and YesPath machine learning builds a model that scores how similar other individuals are to that target group. Model inputs include content consumption as sourced from Bombora, behaviors captured by a YesPath Javascript tag on the marketers’ own Web site and emails, and campaign responses imported from CRM (Salesforce.com only so far) and marketing automation (the first integration will be announced shortly). Selection criteria can also include data such as title imported from CRM. Accounts can be assigned to multiple programs but each individual is assigned to only one program at a time, based on whichever program’s target group they match most closely. This means that individuals from the same company with different personas will be in different programs and potentially receive different experiences.
- stage tracking within programs. In addition to assigning an account list and defining individual selection criteria, program set-up includes creating rules to classify accounts into buying stages. These rules draw on behaviors of all individuals within the account, looking primarily at direct interactions with the company Web site, CRM, and marketing automation. YesPath monitors behaviors as they occur and will reassign the account’s stage as appropriate. All individuals in the same account are considered to be in the same stage in a given program. Although stages could be used to describe a customer journey, the fact that each program has its own stage definitions means they can be used in other ways as well.
- stage-based actions. The final task in program set-up is defining actions to occur when an account reaches a new stage. Web site actions, including banner ads, modals, popups, and sliders, can be executed by YesPath itself, using its Javascript tag to identify visitors and display messages. Other actions would be sent by API to execute Madison Logic display advertising, Salesforce.com sales campaigns or other tasks, marketing automation campaigns, or acquire net new lead names from an external source. The system could apply machine learning to select content delivered by an action, but most YesPath clients have so far preferred to select the content in advance. The system can run split tests to assess alternative actions..
- engagement scores and reporting. YesPath assigns points to interactions such as downloads and page visits. It sums these points for all individuals in an account to create an engagement score that is its primary measure of account activity. For example, program effectiveness is measured by showing the change in engagement after the program began. Other account and program reports show the number of accounts by stage within each program; account details such as stage, days in stage, engagement and visitor counts; distribution of visitors by department and level; interest in different topics; and drill-down to individual activity details. Like other ABM vendors, YesPath says its clients have been very eager to see account reporting on its own, even before any programs were created.
This is an intriguing mix of features. Using intent data to identify active prospects early in the buying cycle makes sense but in practice will miss many potential buyers. This isn’t a fatal flaw, since marketers can advertise to target accounts regardless of whether they show up on intent lists, and internal data from Web, CRM, and marketing automation will add precision once prospects start engaging with the company directly. But it does mean this feature is likely to be less powerful than users might expect.
My greater concern is the system’s approach to journey management. Automatically moving individuals among programs and moving accounts to new program stages sounds great: the system dynamically reacts to individual behaviors without defining every path in advance. But users must manually assign accounts to programs, select the individuals used to train the machine learning models, write stage definition rules, and assign actions to stages and messages to actions. It will take a very savvy user to design these elements so they interact in a way that delivers the desired customer experience. The challenge is even greater because actions can only be triggered by a stage change: this means that even a simple multi-step campaign would require multiple stages with tightly written rules to ensure the timing works as intended and that individuals are not reassigned to other programs midstream. And, since stages are assigned at the account level, additional cleverness would be needed to run people through the program at different times. YesPath managers argue their approach makes it easier to manage complex customer journeys than traditional campaign workflows, but I’m not so sure. Perhaps YesPath will find its niche as a way to manage relatively simple experiences, such as account-based advertising campaigns keyed to the buying cycle.
Pricing of YesPath is based on the number of accounts in the system and starts at $3,000 per month for 500 accounts. The system was launched in March 2016 and had ten clients as of June.
______________________________________________________
* I’m talking here about ABM database and orchestration systems, not ABM data providers or advertising vendors. Data inputs and message delivery are needed regardless of what core marketing systems a client uses.
But marketers whose current tools don’t support ABM will need to something new if they want to participate in the ABM gold rush. This gives ABM database and orchestration specialists an opportunity to sell to clients who would otherwise be uninterested in new core systems. The long term, though often unstated, goal of most ABM specialists is to replace the incumbents as their clients’ primary marketing platforms.* But before they can do that, they need to get their foot in the door by making ABM easier than it would be with clients’ existing tools.
The main function provided by ABM specialists is account-level data aggregation. This in turn makes possible account-level analytics and orchestration. But data and analytics don’t create revenue by themselves, so vendors naturally stress their orchestration features. Hence “plays” from Engagio (discussed here ) and “recipes” in ZenIQ (discussed here). It’s important to recognize that both those systems also build an account-oriented database and provide ABM analytics. They are also similar in relying primarily on external systems to deliver the messages they select. This is a primary difference from conventional marketing automation products, which deliver email and often other types of messages directly. (Special bonus: by relying on marketing automation to deliver their messages, the ABM orchestrators also show that they don’t intend to replace existing marketing automation systems, removing one objection to their purchase. What they don’t say is they are diminishing the role of marketing automation from the central marketing platform to a simple delivery system, clearing the way for the ABM vendors to eventually take over the central role. But don’t tell anyone I told you.)
YesPath is another ABM orchestrator (ABMO?). It too builds an account-oriented database, provides ABM analytics, and selects messages to be delivered by other systems. Of course, every system is unique. Here are some important details that distinguish YesPath:
- focus on unknown prospects. YesPath relies heavily on Bombora intent data to find companies and individuals (or, more precisely, anonymous cookies) that are interested in topics relevant to a marketer’s products. This lets YesPath programs (which are rather unimaginatively called “programs”) determine which companies on the client’s target list are in active buying cycles, even before they have visited the company Web site or responded to an outbound promotion. YesPath can then reach those companies and individuals through a just-announced integration with the Madison Logic display ad network.
- persona-based programs. Marketers set up YesPath programs by uploading a list of target accounts and then defining the selection criteria for individuals to enter the program. These criteria can be considered a persona definition because they identify a set of similar individuals: in this sense, each program relates to a single persona. To create the selection criteria, users select a target audience of people who have shown interest in one or more topics and YesPath machine learning builds a model that scores how similar other individuals are to that target group. Model inputs include content consumption as sourced from Bombora, behaviors captured by a YesPath Javascript tag on the marketers’ own Web site and emails, and campaign responses imported from CRM (Salesforce.com only so far) and marketing automation (the first integration will be announced shortly). Selection criteria can also include data such as title imported from CRM. Accounts can be assigned to multiple programs but each individual is assigned to only one program at a time, based on whichever program’s target group they match most closely. This means that individuals from the same company with different personas will be in different programs and potentially receive different experiences.
- stage tracking within programs. In addition to assigning an account list and defining individual selection criteria, program set-up includes creating rules to classify accounts into buying stages. These rules draw on behaviors of all individuals within the account, looking primarily at direct interactions with the company Web site, CRM, and marketing automation. YesPath monitors behaviors as they occur and will reassign the account’s stage as appropriate. All individuals in the same account are considered to be in the same stage in a given program. Although stages could be used to describe a customer journey, the fact that each program has its own stage definitions means they can be used in other ways as well.
- stage-based actions. The final task in program set-up is defining actions to occur when an account reaches a new stage. Web site actions, including banner ads, modals, popups, and sliders, can be executed by YesPath itself, using its Javascript tag to identify visitors and display messages. Other actions would be sent by API to execute Madison Logic display advertising, Salesforce.com sales campaigns or other tasks, marketing automation campaigns, or acquire net new lead names from an external source. The system could apply machine learning to select content delivered by an action, but most YesPath clients have so far preferred to select the content in advance. The system can run split tests to assess alternative actions..
- engagement scores and reporting. YesPath assigns points to interactions such as downloads and page visits. It sums these points for all individuals in an account to create an engagement score that is its primary measure of account activity. For example, program effectiveness is measured by showing the change in engagement after the program began. Other account and program reports show the number of accounts by stage within each program; account details such as stage, days in stage, engagement and visitor counts; distribution of visitors by department and level; interest in different topics; and drill-down to individual activity details. Like other ABM vendors, YesPath says its clients have been very eager to see account reporting on its own, even before any programs were created.
This is an intriguing mix of features. Using intent data to identify active prospects early in the buying cycle makes sense but in practice will miss many potential buyers. This isn’t a fatal flaw, since marketers can advertise to target accounts regardless of whether they show up on intent lists, and internal data from Web, CRM, and marketing automation will add precision once prospects start engaging with the company directly. But it does mean this feature is likely to be less powerful than users might expect.
My greater concern is the system’s approach to journey management. Automatically moving individuals among programs and moving accounts to new program stages sounds great: the system dynamically reacts to individual behaviors without defining every path in advance. But users must manually assign accounts to programs, select the individuals used to train the machine learning models, write stage definition rules, and assign actions to stages and messages to actions. It will take a very savvy user to design these elements so they interact in a way that delivers the desired customer experience. The challenge is even greater because actions can only be triggered by a stage change: this means that even a simple multi-step campaign would require multiple stages with tightly written rules to ensure the timing works as intended and that individuals are not reassigned to other programs midstream. And, since stages are assigned at the account level, additional cleverness would be needed to run people through the program at different times. YesPath managers argue their approach makes it easier to manage complex customer journeys than traditional campaign workflows, but I’m not so sure. Perhaps YesPath will find its niche as a way to manage relatively simple experiences, such as account-based advertising campaigns keyed to the buying cycle.
Pricing of YesPath is based on the number of accounts in the system and starts at $3,000 per month for 500 accounts. The system was launched in March 2016 and had ten clients as of June.
______________________________________________________
* I’m talking here about ABM database and orchestration systems, not ABM data providers or advertising vendors. Data inputs and message delivery are needed regardless of what core marketing systems a client uses.
Thursday, June 02, 2016
Usermind Makes Journey Orchestration Simple
Maybe you’ve been waiting with increasing impatience for me to finish reviewing the set of Journey Orchestration Engines (JOEs) I first mentioned in March. More likely, it slipped your mind entirely. But I do worry about such things so I’m especially pleased for finish out the set by telling you about Usermind.
I'm not saying that Usermind calls itself a JOE. Its self-description is “the first unified platform for orchestrating business operations”. But the company uses the language of journeys and customer data stores. So although they see themselves as enabling all kinds of business processes, I think it’s fair to view them largely in the context of customer management.
Usermind is all about simplicity. Its main screen sets the tone by offering just three tabs: Analytics, Journeys, and Integration. Deploying the system actually starts with the last of these, Integration, which is where the user connects to external systems that are both data sources and execution engines. The company lists about a dozen standard integrations including major marketing automation, CRM, email, customer service, collaboration, and analytics systems. Another half-dozen are “coming soon.”
A key feature of Usermind is it makes integration easy by reading the contents of the source systems automatically, so any custom data elements or objects are incorporated without user effort. This also means it adjusts to changes in those systems automatically. Users do build maps that show which fields to use to link customers (or other entities) across systems: for example, a map might use email address to link marketing automation to CRM, and customer ID to link CRM to customer service. The system can also map on combinations of fields and do fuzzy matching on inconsistent data. There can be separate maps for individuals, companies, products, customers, partners, or whatever other entities the user wants to work with. Usermind figures out relationships among tables or objects within each source system, so users simply see a list of available fields without having worry about the underlying data structures.
Once the maps are in place, Usermind copies selected data elements into its own database, where they are available to use in journeys. Each journey is a sequence of milestones, which can each contain one or more rules. Each rule has selection conditions and one or more actions to take if the conditions are met. Actions can push data or tasks to back to the source systems. Rules can be triggered by events or executed on schedule.
And that’s pretty much it. The Analytics tab reports on movement of customers through journeys, providing counts, conversion rates and drop-out rates for each milestone. It also analyzes the impact of actions on results. The system can be connected to business intelligence tools for more advanced reporting. But there’s no predictive analytics, content creation, or message execution. True to its description, Usermind is designed to orchestrate actions in other systems, not take actions itself.
Don’t let that simplicity fool you. Usermind (and other JOEs) address the critical challenge of unifying customer data from different sources and coordinating customer treatments. Tools to make this easy are rare; tools to send emails and deliver other messages are not. So Usermind fills an important gap – which is why the company has attracted $22 million in venture funding since it was founded in 2013, and why its investors waited until this year for it to launch the actual product. (Whether they waited patiently is a question I didn’t ask.) As of March, the company reported 15 live customers and was actively looking for more.
You may be wondering whether Usermind can truly be called a JOE since I've defined the essence of JOE-ness as a system that discovers the customer journey for itself rather than relying on the user to define it. Usermind doesn’t pass that test. In fact, Usermind journeys are individual processes rather than an overview of the customer’s lifetime experience. But Usermind still looks JOE-ish because it’s capturing events that occur naturally, not creating its own events like messages in a nurture flow. And its ability to use the journey as a framework for managing customer treatments is exactly what JOEs are all about. So marketers looking for a JOE should put Usermind on their list.
 |
| Usermind Journey |
I'm not saying that Usermind calls itself a JOE. Its self-description is “the first unified platform for orchestrating business operations”. But the company uses the language of journeys and customer data stores. So although they see themselves as enabling all kinds of business processes, I think it’s fair to view them largely in the context of customer management.
Usermind is all about simplicity. Its main screen sets the tone by offering just three tabs: Analytics, Journeys, and Integration. Deploying the system actually starts with the last of these, Integration, which is where the user connects to external systems that are both data sources and execution engines. The company lists about a dozen standard integrations including major marketing automation, CRM, email, customer service, collaboration, and analytics systems. Another half-dozen are “coming soon.”
A key feature of Usermind is it makes integration easy by reading the contents of the source systems automatically, so any custom data elements or objects are incorporated without user effort. This also means it adjusts to changes in those systems automatically. Users do build maps that show which fields to use to link customers (or other entities) across systems: for example, a map might use email address to link marketing automation to CRM, and customer ID to link CRM to customer service. The system can also map on combinations of fields and do fuzzy matching on inconsistent data. There can be separate maps for individuals, companies, products, customers, partners, or whatever other entities the user wants to work with. Usermind figures out relationships among tables or objects within each source system, so users simply see a list of available fields without having worry about the underlying data structures.
Once the maps are in place, Usermind copies selected data elements into its own database, where they are available to use in journeys. Each journey is a sequence of milestones, which can each contain one or more rules. Each rule has selection conditions and one or more actions to take if the conditions are met. Actions can push data or tasks to back to the source systems. Rules can be triggered by events or executed on schedule.
 |
| Usermind Rule |
And that’s pretty much it. The Analytics tab reports on movement of customers through journeys, providing counts, conversion rates and drop-out rates for each milestone. It also analyzes the impact of actions on results. The system can be connected to business intelligence tools for more advanced reporting. But there’s no predictive analytics, content creation, or message execution. True to its description, Usermind is designed to orchestrate actions in other systems, not take actions itself.
Don’t let that simplicity fool you. Usermind (and other JOEs) address the critical challenge of unifying customer data from different sources and coordinating customer treatments. Tools to make this easy are rare; tools to send emails and deliver other messages are not. So Usermind fills an important gap – which is why the company has attracted $22 million in venture funding since it was founded in 2013, and why its investors waited until this year for it to launch the actual product. (Whether they waited patiently is a question I didn’t ask.) As of March, the company reported 15 live customers and was actively looking for more.
You may be wondering whether Usermind can truly be called a JOE since I've defined the essence of JOE-ness as a system that discovers the customer journey for itself rather than relying on the user to define it. Usermind doesn’t pass that test. In fact, Usermind journeys are individual processes rather than an overview of the customer’s lifetime experience. But Usermind still looks JOE-ish because it’s capturing events that occur naturally, not creating its own events like messages in a nurture flow. And its ability to use the journey as a framework for managing customer treatments is exactly what JOEs are all about. So marketers looking for a JOE should put Usermind on their list.
Intercom "Smart Campaigns" Replace Decision Trees: Interesting But Not Perfect
I got all excited when I saw this description from messaging vendor Intercom about new "smart campaigns" in marketing automation that automatically send the best message at the best time in the best channel to each person without pre-designed campaign flows. Their critique of the current process -- essentially that fixed flows are too complicated -- is spot on.
Alas, a deeper look left me a little disappointed. Here's how Intercom describes the smart campaign process:
This is still pretty impressive but it puts most of the work back on the user to figure out those triggers. It doesn't automatically adjust the core priority ranking (which drives the default message sequence) based on user attributes or behaviors. I'm sure that clever trigger design could achieve pretty much any use case I could imagine, but it means all the thought I previously put into building clever campaign flows now goes into building clever triggers (and to predicting the customer experience resulting from interactions among those triggers). So the Promised Land of fully automated, optimized campaign design still hasn't been reached.
Note: I haven't spoken with Intercom. I'll try to find time for that and to write a real review. But I did want to put this out because it's a good example of people thinking about alternatives to the current marketing automation campaign flows, even if they haven't found a perfect replacement.
Further note: I did subsequently speak with Intercom to learn more about their system. It turns out that my initial description, presented above, was accurate. They do make it pretty easy to connect with Web, mobile app, and other data sources and to send messages by email, text, and in-app. They also let users assign goals to each campaign as a whole and to individual messages, which helps to report on campaign success and to optimize treatments within a campaign. So they do have some nice features that make effective messaging much easier than standard marketing automation systems. But fully automated, self-optimizing campaigns, they are not.
Alas, a deeper look left me a little disappointed. Here's how Intercom describes the smart campaign process:
- First, choose the people you want to message and the goal you want to achieve, e.g. send a series of messages to people who start a trial to get them to become paying customers.
- Then decide how often you would like them to receive messages, e.g. you may want to send, at most, a message every two days.
- Choose triggers for your messages, based on time, behavior or interaction with other messages.
- Then simply rank them by priority, with the most important message listed first.
- When people are eligible to receive a new message, Intercom looks at all the messages in the campaign, identifies the ones the customer matches the rules for and sends them the highest priority message.
This is still pretty impressive but it puts most of the work back on the user to figure out those triggers. It doesn't automatically adjust the core priority ranking (which drives the default message sequence) based on user attributes or behaviors. I'm sure that clever trigger design could achieve pretty much any use case I could imagine, but it means all the thought I previously put into building clever campaign flows now goes into building clever triggers (and to predicting the customer experience resulting from interactions among those triggers). So the Promised Land of fully automated, optimized campaign design still hasn't been reached.
Note: I haven't spoken with Intercom. I'll try to find time for that and to write a real review. But I did want to put this out because it's a good example of people thinking about alternatives to the current marketing automation campaign flows, even if they haven't found a perfect replacement.
Further note: I did subsequently speak with Intercom to learn more about their system. It turns out that my initial description, presented above, was accurate. They do make it pretty easy to connect with Web, mobile app, and other data sources and to send messages by email, text, and in-app. They also let users assign goals to each campaign as a whole and to individual messages, which helps to report on campaign success and to optimize treatments within a campaign. So they do have some nice features that make effective messaging much easier than standard marketing automation systems. But fully automated, self-optimizing campaigns, they are not.
Wednesday, May 11, 2016
Pointillist Journey Orchestration Discovers Customer Paths for Itself (Marketing Automation is Doomed, I Tell You)
This post will resume the tour I started in March of journey orchestration engines – our new friend JOE. But first I’ll interrupt myself to announce that I have officially decided to predict that JOEs will replace campaign management and marketing automation as the core system for marketing departments. I usually hedge my bets with this sort of prediction, but will abandon my typical caution because I’m convinced that campaign management and marketing automation are too deeply rooted in the old world of batch list generation to meet today’s need for continuous optimization of customer treatments. Their core architectures just aren’t up to it.
I’m not saying that JOEs will have no competition. Plenty of other vendors have the potential to make the transition – in particular, products developed for real time interactions and Web personalization. I am saying the competition won’t come from today’s campaign management and marketing automation leaders.*
Now that I’ve shared this exciting bit of news with you, let’s get back to the topic at hand. That would be Pointillist, a just-released “customer intelligence platform” that has been incubating inside financial services technology vendor Altisource since 2014.
As Pointillist’s self-chosen label suggests, its own roots are in customer data analytics, not execution. Sure enough, the system is built around a custom data structure that (if my notes are accurate) they describe as a “combination graph relational time series”, which certainly sounds like something out of Dr. Who.
Put in terms simple enough for me to understand, Pointillist stores all data as events, which can have attributes including customers, products and campaigns. Different event types contain different sets of attributes but there are no formal data tables or relationships among tables. This sounds broadly like Hadoop and other NoSQL data stores, although I’m sure there are Important Technical Differences that matter deeply to people care about such things. What matters from a marketer’s perspective is this approach makes it easy to add new types of information and to update information very quickly.
Also as with Hadoop and friends, the Pointillist data store needs some added structure to allow fast access and analysis, and that structure imposes some limitations. Pointillist has optimized for customer analysis, meaning that customer behaviors can be analyzed almost instantly but combining information about customers is harder. For example, it could be tough to find out which products two customers bought in common. All data is stored persistently on a disk somewhere in the Amazon cloud, but accessible data is loaded into memory. This makes things really quick.
That’s probably more than you care or need to know about Pointillist’s technology. Let’s get back to the surface where things are bright and shiny. What makes Pointillist a journey orchestration engine is that it can describe and act against customer journeys. The acting part is especially important, because it makes Pointillist more than simply an analysis tool.

What Pointillist really does from a user point of view is let you pick sets of customers and events to analyze. Users drag the events onto a workspace and connect them with lines to indicate the sequence to analyze. The system then scans its data to find how many customers had an instance of each event and draws lines whose thickness indicates how many passed customers from one event to the next. In other words, it creates a journey map.
Or, and this is my favorite part, you can tell Pointillist to discover the most important paths on its own. It does this usingmagic machine learning to determine which paths have the highest combination of frequency, exclusivity, and correlation to a goal (a user-specified event). Users can adjust the balance among those three factors and can further train the algorithm by telling it which connections they feel are important. Because Pointillist is doing the analysis in memory and considerately visualizes its results, you can watch it test different connections until it settles on a final set. Hours of fun, for sure.
But there’s more. Pointillist can report on the disposition of people within each event, replacing its icon with a little circle graph showing how many people reached the final goal, moved to the next event (but never reached the goal), dropped out, or stayed behind. It can also display other statistics in graphs next to the flow diagram, as well as letting users analyze subsets of the audience or even a trace the path of a single individual. The analysis can run backwards or forwards, finding either where an initial set of customers ended up or where a final set of customers came from. Heck, that’s weeks of fun when you think about it.
Taking action within Pointillist works exactly as you’d think: for any event on the chart, the system can generate a list of customers that it will send to an external system. The list could include all people in the event or a subset with specified behaviors. When I spoke with Pointillist a few weeks ago, the list would be a file export, but API connections were close to being ready. They’ll probably be done by the time you read this.
Also under development when we spoke was an automated cluster builder that would find clusters most related to (or distant from) the target event. This is different, and often more useful, than traditional clusters that find groups that are similar or distant from each other. Pointillist was also working on letting users create calculated variables, such as a lifetime value or engagement score, that would be available for analysis or segmentation. And on automated tools to help load unstructured data and clean dirty data. And on connectors to push data out to other systems. And on fuzzy matching to supplement the existing, and quite powerful, tools to unify customer data from different sources. Because nobody ever had too much fun.
Speaking of data loading, Pointillist has its own Javascript tag to capture Web behaviors, uses third party connectors to import data from many common systems, and can import batch files from nearly any source. Mapping new event types requires some basic technical skills but Pointillist is working to make it simpler. While APIs to push data to other systems are under development, APIs that let external systems pull data from Pointillist are already available. These can access customer data but not other data types (remember those special data structures?)
In short, Pointillist both builds a robust, unified customer database and presents exceptional tools to analyze and act on the customer journey. It is the very model of a modern journey orchestrator.
_______________________________________________________________________________
*Nor, to be perfectly clear, am I saying that campaign management and marketing automation systems will go away. They will simply retreat to the execution layer where they will deliver emails and other outbound messages, playing an important role alongside other channel delivery systems like Web sites and call centers. But the fundamental decisions about which messages to send will be made by the orchestration engines.
I’m not saying that JOEs will have no competition. Plenty of other vendors have the potential to make the transition – in particular, products developed for real time interactions and Web personalization. I am saying the competition won’t come from today’s campaign management and marketing automation leaders.*
Now that I’ve shared this exciting bit of news with you, let’s get back to the topic at hand. That would be Pointillist, a just-released “customer intelligence platform” that has been incubating inside financial services technology vendor Altisource since 2014.
As Pointillist’s self-chosen label suggests, its own roots are in customer data analytics, not execution. Sure enough, the system is built around a custom data structure that (if my notes are accurate) they describe as a “combination graph relational time series”, which certainly sounds like something out of Dr. Who.
Put in terms simple enough for me to understand, Pointillist stores all data as events, which can have attributes including customers, products and campaigns. Different event types contain different sets of attributes but there are no formal data tables or relationships among tables. This sounds broadly like Hadoop and other NoSQL data stores, although I’m sure there are Important Technical Differences that matter deeply to people care about such things. What matters from a marketer’s perspective is this approach makes it easy to add new types of information and to update information very quickly.
Also as with Hadoop and friends, the Pointillist data store needs some added structure to allow fast access and analysis, and that structure imposes some limitations. Pointillist has optimized for customer analysis, meaning that customer behaviors can be analyzed almost instantly but combining information about customers is harder. For example, it could be tough to find out which products two customers bought in common. All data is stored persistently on a disk somewhere in the Amazon cloud, but accessible data is loaded into memory. This makes things really quick.
That’s probably more than you care or need to know about Pointillist’s technology. Let’s get back to the surface where things are bright and shiny. What makes Pointillist a journey orchestration engine is that it can describe and act against customer journeys. The acting part is especially important, because it makes Pointillist more than simply an analysis tool.

What Pointillist really does from a user point of view is let you pick sets of customers and events to analyze. Users drag the events onto a workspace and connect them with lines to indicate the sequence to analyze. The system then scans its data to find how many customers had an instance of each event and draws lines whose thickness indicates how many passed customers from one event to the next. In other words, it creates a journey map.
Or, and this is my favorite part, you can tell Pointillist to discover the most important paths on its own. It does this using
But there’s more. Pointillist can report on the disposition of people within each event, replacing its icon with a little circle graph showing how many people reached the final goal, moved to the next event (but never reached the goal), dropped out, or stayed behind. It can also display other statistics in graphs next to the flow diagram, as well as letting users analyze subsets of the audience or even a trace the path of a single individual. The analysis can run backwards or forwards, finding either where an initial set of customers ended up or where a final set of customers came from. Heck, that’s weeks of fun when you think about it.
Taking action within Pointillist works exactly as you’d think: for any event on the chart, the system can generate a list of customers that it will send to an external system. The list could include all people in the event or a subset with specified behaviors. When I spoke with Pointillist a few weeks ago, the list would be a file export, but API connections were close to being ready. They’ll probably be done by the time you read this.
Also under development when we spoke was an automated cluster builder that would find clusters most related to (or distant from) the target event. This is different, and often more useful, than traditional clusters that find groups that are similar or distant from each other. Pointillist was also working on letting users create calculated variables, such as a lifetime value or engagement score, that would be available for analysis or segmentation. And on automated tools to help load unstructured data and clean dirty data. And on connectors to push data out to other systems. And on fuzzy matching to supplement the existing, and quite powerful, tools to unify customer data from different sources. Because nobody ever had too much fun.
Speaking of data loading, Pointillist has its own Javascript tag to capture Web behaviors, uses third party connectors to import data from many common systems, and can import batch files from nearly any source. Mapping new event types requires some basic technical skills but Pointillist is working to make it simpler. While APIs to push data to other systems are under development, APIs that let external systems pull data from Pointillist are already available. These can access customer data but not other data types (remember those special data structures?)
In short, Pointillist both builds a robust, unified customer database and presents exceptional tools to analyze and act on the customer journey. It is the very model of a modern journey orchestrator.
_______________________________________________________________________________
*Nor, to be perfectly clear, am I saying that campaign management and marketing automation systems will go away. They will simply retreat to the execution layer where they will deliver emails and other outbound messages, playing an important role alongside other channel delivery systems like Web sites and call centers. But the fundamental decisions about which messages to send will be made by the orchestration engines.
Wednesday, April 13, 2016
Thunderhead ONE Provides Powerful Journey Orchestration
As I wrote a couple of posts back, I’ve recently noticed a new set of vendors offering “journey optimization engines”*. The key feature of these systems is they select customer treatments based on movement through a journey map. The treatments are usually executed through external systems such as email service providers, CRM, or Web content management. The systems also assemble the unified customer database needed to track customer journeys. This, of course, is a function they share with Customer Data Platforms. But CDPs don’t necessarily have journey mapping or treatment selection functions. On the other hand, journey optimization engines don’t always expose their data to external systems, which is a core requirement for CDPs. Journey optimization engines also provide at least some tools to analyze customer journeys and choose the best customer treatments. These may include predictive models, machine learning, and automatic creation of journey maps, but don’t have to.
Thunderhead ONE Engagement Hub is a charter member of this new little club. UK-headquartered Thunderhead itself was founded way back in 2001 and launched its original customer engagement product (highly personalized customer communications such as account statements) in 2004. ONE was developed by a U.S.-based engineering team. It was released in Europe in 2015 and in the U.S. earlier this year.
Let’s look at how ONE handles the three core journey optimization functions:
- Data assembly. ONE provides its own Javascript tag to capture Web and email interactions and a SDK to connect with mobile apps. Other systems can feed data into ONE using a REST API or batch file imports. There are prebuilt API connectors for Salesforce.com CRM, Microsoft Dynamics CRM, and SAP Cloud for Customer. The system will automatically replicate the structure of imported data, maintaining relationships between different data elements. This allows ONE to store nearly any kind of data including not just customer attributes and identifiers, but also interaction and purchase details, touchpoint configurations, and product information.
Data is time-stamped to allow trending and give access to previous values of individual elements. Users can define calculations to create derived values such as engagement score, customer type, preferences, or interests. In addition to storing the imported information in a persistent database, ONE can lets users define in-memory profiles available for real-time access during interactions. These are updated immediately as new data is gathered, so the system is always working with the most current information.
ONE can link data using customer identifiers from different sources so long as there is a common element somewhere in the chain, such as an email address that is attached to a Web browser cookie through a form fill and to a mobile device through app registration. This allows the system to start tracking anonymous users when they first appear and later connect them to a personal profile when they identify themselves. But ONE does not standardize customer attributes, such as name or address, or use “fuzzy” matching to infer likely relationships.
All told, this is an exceptionally broad set of data management features. Many systems that build profiles – both CDPs and journey optimization engines – lack ONE's ability to store information about entities such as touchpoints or products. Nor do they always provide both a persistent data store and in-memory access. And while most can stitch together identities using shared identifiers, some rely on external systems to provide a common ID.

- Journey mapping. ONE lets users assign journey stages to activities and then classify interactions by activity type. Interactions can also be tagged with other attributes such as channel, product, and marketing asset. The system uses this information to create many varieties of journey maps, including one that shows movement between stages broken out by channels, which is delightfully similar to the Customer Experience Matrix** I’ve been working with since 2006.*** Other versions filter the inputs to show maps for specific products, customer segments, or touchpoints within a channel (such as specific Web sites, retail stores, or phone agents). Maps can also compare attributes of different groups, such as customers who advanced towards purchase vs those who dropped out. Slicing the data in yet another way, maps can show the impact on engagement score of specific actions. Hours of fun, eh?
- Execution. Users can create “conversations” that send messages to customers who match a specified combination of journey stage, customer attributes, and channels. Eligibility and relevance rules can ensure the chosen messages are truly appropriate. One conversation can include several messages in different channels. Message contents can be drawn from a repository within ONE or from an external asset library.
The system uses machine learning to estimate how each customers will respond to each conversation and to calculate the value of the conversation. An arbitration function can then find the highest value conversation in each situation. The system can deploy conversations in real time, presenting CRM agents with recommended actions (along with a detailed customer profile and history) or Web pages with personalized contents (deployed in user-specified locations on the page). Personalized content and data can also be pushed to other execution systems such as email through API connections, either in batch or real time. External systems can access individual customer records through the ONE API. Data can also be extracted from ONE to standard SQL databases, which external systems could then query.
Pricing for ONE starts at $30,000 per year and is based on the volume of interactions and personalization recommendations, with unit costs varying by channel. The system has 38 clients in Europe and about a dozen in North America.
______________________________________________________________________________
*I would love to call these JOEs but don’t have the heart to inflict another obscure acronym on the industry. You’re welcome.
** Originally developed by my colleague Michael Hoffman. Click here for his take on it.
*** I’m not suggesting that Thunderhead based their map on the Customer Experience Matrix. Many people have come up with similar ideas. I do like to think that Hoffman and I were ahead of our time.
Thunderhead ONE Engagement Hub is a charter member of this new little club. UK-headquartered Thunderhead itself was founded way back in 2001 and launched its original customer engagement product (highly personalized customer communications such as account statements) in 2004. ONE was developed by a U.S.-based engineering team. It was released in Europe in 2015 and in the U.S. earlier this year.
Let’s look at how ONE handles the three core journey optimization functions:
- Data assembly. ONE provides its own Javascript tag to capture Web and email interactions and a SDK to connect with mobile apps. Other systems can feed data into ONE using a REST API or batch file imports. There are prebuilt API connectors for Salesforce.com CRM, Microsoft Dynamics CRM, and SAP Cloud for Customer. The system will automatically replicate the structure of imported data, maintaining relationships between different data elements. This allows ONE to store nearly any kind of data including not just customer attributes and identifiers, but also interaction and purchase details, touchpoint configurations, and product information.
Data is time-stamped to allow trending and give access to previous values of individual elements. Users can define calculations to create derived values such as engagement score, customer type, preferences, or interests. In addition to storing the imported information in a persistent database, ONE can lets users define in-memory profiles available for real-time access during interactions. These are updated immediately as new data is gathered, so the system is always working with the most current information.
ONE can link data using customer identifiers from different sources so long as there is a common element somewhere in the chain, such as an email address that is attached to a Web browser cookie through a form fill and to a mobile device through app registration. This allows the system to start tracking anonymous users when they first appear and later connect them to a personal profile when they identify themselves. But ONE does not standardize customer attributes, such as name or address, or use “fuzzy” matching to infer likely relationships.
All told, this is an exceptionally broad set of data management features. Many systems that build profiles – both CDPs and journey optimization engines – lack ONE's ability to store information about entities such as touchpoints or products. Nor do they always provide both a persistent data store and in-memory access. And while most can stitch together identities using shared identifiers, some rely on external systems to provide a common ID.

- Journey mapping. ONE lets users assign journey stages to activities and then classify interactions by activity type. Interactions can also be tagged with other attributes such as channel, product, and marketing asset. The system uses this information to create many varieties of journey maps, including one that shows movement between stages broken out by channels, which is delightfully similar to the Customer Experience Matrix** I’ve been working with since 2006.*** Other versions filter the inputs to show maps for specific products, customer segments, or touchpoints within a channel (such as specific Web sites, retail stores, or phone agents). Maps can also compare attributes of different groups, such as customers who advanced towards purchase vs those who dropped out. Slicing the data in yet another way, maps can show the impact on engagement score of specific actions. Hours of fun, eh?
- Execution. Users can create “conversations” that send messages to customers who match a specified combination of journey stage, customer attributes, and channels. Eligibility and relevance rules can ensure the chosen messages are truly appropriate. One conversation can include several messages in different channels. Message contents can be drawn from a repository within ONE or from an external asset library.
The system uses machine learning to estimate how each customers will respond to each conversation and to calculate the value of the conversation. An arbitration function can then find the highest value conversation in each situation. The system can deploy conversations in real time, presenting CRM agents with recommended actions (along with a detailed customer profile and history) or Web pages with personalized contents (deployed in user-specified locations on the page). Personalized content and data can also be pushed to other execution systems such as email through API connections, either in batch or real time. External systems can access individual customer records through the ONE API. Data can also be extracted from ONE to standard SQL databases, which external systems could then query.
Pricing for ONE starts at $30,000 per year and is based on the volume of interactions and personalization recommendations, with unit costs varying by channel. The system has 38 clients in Europe and about a dozen in North America.
______________________________________________________________________________
*I would love to call these JOEs but don’t have the heart to inflict another obscure acronym on the industry. You’re welcome.
** Originally developed by my colleague Michael Hoffman. Click here for his take on it.
*** I’m not suggesting that Thunderhead based their map on the Customer Experience Matrix. Many people have come up with similar ideas. I do like to think that Hoffman and I were ahead of our time.
Subscribe to:
Posts (Atom)


