Long-time readers of this blog know that I have a deep fondness for
QlikView as a tool that lets business analysts do work that would otherwise require IT support. QlikView has a very fast, scalable database and excellent tools to create reports and graphs. But quite a few other systems offer at least one of these.*
What really sets QlikView apart is its scripting language, which lets analysts build processing streams to combine and transform multiple data sources. Although QlikView is far from comparable with enterprise-class data integration tools like
Informatica, its scripts allow sophisticated data preparation that is vastly too complex to repeat regularly in Excel. (See my post
What Makes QlikTech So Good for more on this.)
Lyzasoft Lyza is the first product I’ve seen that might give QlikView a serious run for its money. Lyza doesn’t have scripts, but users can achieve similar goals by building step-by-step process flows to merge and transform multiple data sources. The flows support different kinds of joins and Excel-style formulas, including if statements and comparisons to adjacent rows. This gives Lyza enough power to do most of the manipulations an analyst would want in cleaning and extending a data set.
Lyza also has the unique and important advantage of letting users view the actual data at every step in the flow, the way they’d see rows on a spreadsheet. This makes it vastly easier to build a flow that does what you want. The flows can also produce reports, including tables and different kinds of graphs, which would typically be the final result of an analysis project.
All of that is quite impressive and makes for a beautiful demonstration. But plenty of systems can do cool things on small volumes of data – basically, they throw the data into memory and go nuts. Everything about Lyza, from its cartoonish logo to its desktop-only deployment to the online store selling at a sub-$1,000 price point, led me to expect the same. I figured this would be another nice tool for little data sets – which to me means 50,000 to 100,000 rows – and nothing more.
But it seems that’s not the case. Lyzasoft CEO Scott Davis tells me the system regularly runs data sets with tens of millions of rows and the biggest he’s used is 591 million rows and around 7.5-8 GB.
A good part of the trick is that Lyza is NOT an in-memory database. This means it’s not bound by the workstation’s memory limits. Instead, Lyza uses a columnar structure with indexes on non-numeric fields. This lets it read required data from the disk very quickly. Davis also said that in practice most users either summarize or sample very large data sets early in their data flows to get down to more manageable volumes.
Summarizing the data seems a lot like cheating when you’re talking about scalability, so that didn’t leave me very convinced. But you can download a free 30 day trial of Lyza, which let me test it myself.
Bottom line: my embarrassingly ancient desktop (2.8 GHz CPU, 2 GB RAM, Windows XP) loaded a 400 MB CSV file with about 430,000 rows in just over 6 minutes. That’s somewhat painful, but it does suggest you could load 4 GB in an hour – a practical if not exactly desirable period. The real issue is that each subsequent step could take similar amounts of time: copying my 400 MB set to a second step took a little over 2 minutes and, more worrisome, subsequent filters took the same 2 minutes even though they reduced the record count to 85,000 then 7,000 then 50. This means a complete processing flow on a large data set could run for hours.
Still, a typical real-world scenario would be to do development work on small samples, and then only run a really big flow once you knew you had it right. So even the load time for subsequent steps is not necessarily a show-stopper.
Better news is that rerunning an existing filter with slightly different criteria took just a few seconds, and even rerunning the existing flow from the start was much faster than the first time through. Users can also rerun all steps after a given point in the flow. This works because Lyza saves the intermediate data sets. It means that analysts can efficiently explore changes or extend an existing project without waiting for the entire flow to re-execute. It’s not as nice as running everything on a lightning-fast data server, but most analysts would find it gives them all the power they need.
As a point of comparison, loading that same 400 MB CSV file took almost 11 minutes with QlikView. I had forgotten how slowly QlikView loads text files, particularly on my limited CPU. On the other hand, loading a 100 MB Excel spreadsheet took about 90 seconds for Lyza vs. 13 seconds in QlikView. QlikView also compressed the 400 MB to 22 MB on disk and about 50 MB in memory, whereas Lyza more than doubled data to 960 MB of disk, due mostly to indexes. Memory consumption in Lyza rose only about 10 MB.
Of course, compression ratios for both QlikView and Lyza depend greatly on the nature of the data. This particular set had lots of blanks and Y/N fields. The result was much more compression than I usually see in QlikView and, I suspect, more expansion than usual in Lyza. In general, Lyza seems to make little use of data compression, which is usually a key advantage of columnar databases. Although this seems like a problem today, it also means there's an obvious opportunity for improvement as the system finds itself dealing with larger data sets.
What I think this boils down to is that Lyza can effectively handle multi-gigabyte data volumes on a desktop system. The only reason I’m not being more definite is I did see a lot of pauses, most accompanied by 100% CPU utilization, and occasional spikes in memory usage that I could only resolve by closing the software and, once or twice, by rebooting. This happened when I was working with small files as well as the large ones. It might have been the auto-save function, my old hardware, crowded disk drives, or Windows XP. On the other hand, Lyza is a young product (released September 2008) with only a dozen or so clients, so bugs would not be surprising. I'm certainly not ready to say Lyza doesn't have them.
Tracking down bugs will be harder because Lyza also runs on Linux and Mac systems. In fact, judging by the Mac-like interface, I suspect it wasn't developed on a Windows platform. According to Davis, performance isn’t very sensitive to adding memory beyond 1 GB, but high speed disk drives do help once you get past 10 million rows or so. The absolute limit on a 32 bit system is about 2 billion rows, a constraint related to addressable memory space (2^31 = about 2 billion) rather than anything peculiar to Lyza. Lyza can also run on 64 bit servers and is certified on Intel multi-core systems.
Enough about scalability. I haven’t done justice to Lyza’s interface, which is quite good. Most actions involve dragging objects into place, whether to add a new step to a process flow, move a field from one flow stage to the next, or drop measures and dimensions onto a report layout. Being able to see the data and reports instantly is tremendously helpful when building a complex processing flow, particularly if you’re exploring the data or trying to understand a problem at the same time. This is exactly how most analysts work.
Lyza also provides basic statistical functions including descriptive statistics, correlation and Z-test scores, a mean vs. standard deviation plot, and stepwise regression. This is nothing for
SAS or
SPSS to worry about; in fact, even Excel has more options. But it’s enough for most purposes. Similarly, data visualization is limited compared to a Tableau or ADVIZOR, but allows some interactive analysis and is more than adequate for day-to-day purposes.
Users can combine several reports onto a single dashboard, adding titles and effects similar to a Powerpoint slide. The report remains connected to the original workflow but doesn’t update automatically when the flow is rerun.
Intriguingly, Lyza can also display the lineage of a table or chart value. It traces the data from its source through all subsequent workflow steps, listing any transformations or selections applied along the way. Davis sees this as quickly answering the ever-popular question, “Where did that number come from?” Presumably this will leave more time to discuss American Idol.
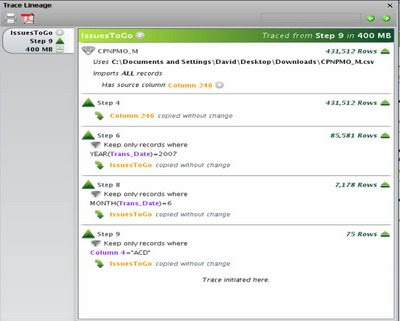
Users can also link one workflow to another by simply dragging an object onto a new worksheet. This is a very powerful feature, since it lets users break big workflows into pieces and lets one workflow feed data into several others. The company has just taken this one step further by adding a collaboration server, Lyza Commons, that lets different users share workflows and reports. Reports show which users send and receive data from other users, as well as which data sets send and receive information from other data sets.
Those reports are more than just neat: they're documenting data flows that are otherwise lost in the “shadow IT” which exists outside of formal systems in most organizations. Combined with lineage tracing, this is where IT departments and auditors should start to find Lyza really interesting.
A future version of Commons will also let non-Lyza users view Lyza reports over the Web – further extending Lyza beyond the analyst’s personal desktop to be an enterprise resource. Add in the 64-bit capability, an API to call Lyza from other systems, and some other tricks the company isn’t ready to discuss in public, and there’s potential here to be much more than a productivity tool for analysts.
This brings us back to pricing. If you were reading closely, you noticed that little comment about Lyza being priced under $1,000. Actually there are two versions: a $199 Lyza Lite that only loads from Microsoft Excel, Access and text files, and the $899 regular version that can also connect to standard relational databases and other ODBC sources and includes the API.
This isn’t quite as cheap as it sounds because these are one year subscriptions. But even so, it is an entry cost well below the several tens of thousands of dollars you’d pay to get started with full versions of QlikView or ADVIZOR, and even a little cheaper than Tableau. The strategy of using analysts’ desktop as a beachhead is obvious, but that doesn’t make it any less effective.
So, should my friends at QlikView be worried? Not right away – QlikView is a vastly more mature product with many features and capabilities that Lyza doesn’t match, and probably can’t unless it switches to an in-memory database. But analysts are QlikView’s beachhead too, and there’s probably not enough room on their desktops for both systems. With a much lower entry price and enough scalability, data manipulation and analysis features to meet analysts’ basic needs, Lyza could be the easier one to pick. And that would make QlikView's growth much harder.
----------------------------
*
ADVIZOR Solutions and
Tableau Software have excellent visualization with an in-memory database, although they’re not so scalable.
PivotLink,
Birst and
LucidEra are on-demand systems that are highly scalable, although their visualization is less sophisticated. Here are links to my reviews:
ADVIZOR ,
Tableau,
PivotLink,
Birst and LucidEra.



