Remember when I asked two weeks ago whether predictive models are becoming a commodity? Here’s another log for that fire: Model Factory from Modern Analytics, which promises as many models as you want for a flat fee starting at $5,000 per month. You heard that right: an all-you-can eat, fixed-price buffet for predictive models. Can free toasters* and a loyalty card be far behind?
Of course, some buffets sell better food than others. So far as I can tell, the models produced by Model Factory are quite good. But buffets also imply eating more than you should. As Model Factory’s developers correctly point out, many organizations could healthily consume a nearly unlimited number of models. Model Factory is targeted at firms whose large needs can’t be met at an acceptable cost by traditional modeling technologies. So the better analogy might be Green Revolution scientists increasing food production to feed the starving masses.
In any case, the real questions are what Model Factory does and how. The "what" is pretty simple: it builds a large number of models in a fully automated fashion. The "how" is more complicated. Model Factory starts by importing data in known structures, so users still need to set up the initial inputs and do things like associate customer identities from different systems. Modern Analytics has staff to help with that, but it can still be a substantial task. The good news is that set-up is done only when you’re defining the modeling process or adding new sources, so the manual work isn't repeated each time a model is built or records are scored. Better still, Modern Analytics has experience connecting to APIs of common data sources such as Salesforce.com, so a new feed from a familiar source usually takes just a few hours to set up. Model Factory stores the loaded data in its own database. This means models can use historical data without reloading all data from scratch before each update.
Once the data flow is established, users specify the file segments to model against and the types of predictions. The predictions usually describe likelihood of actions such as purchasing a specific product but they could be something else. Again there’s some initial skilled work to define the model parameters but the process then runs automatically. During a typical run, Model Factory evaluates the input data, does data prep such as treating outliers and transforming variables, builds new models, checks each model for usable results, and scores customer records for models that pass.
The quality check is arguably the most important part of the process, because that’s what prevents Model Factory from blindly producing bad scores due to inadequate data, quality problems, or other unanticipated issues. Model Factory flags bad models – measured by traditional statistical methods like the c-score – and gives users some information their results. It’s then up to the human experts to dig further and either accept the model as is or make whatever fixes are required. Scores from passing models are pushed to client systems in files, API calls, or whatever else has been set up during implementation.
If you’ve been around the predictive modeling industry for a while, you know that automated model development has been available in different forms for long time. Indeed, Model Factory's own core engine was introduced five years ago. What made Model Factory special, then and now, is automating the end-to-end process at high scale. How high? There's no simple answer because the company can adjust the hardware to provide whatever performance a client requires. In addition to hardware, performance is driven by types of models, number of records, and size of each record. A six-processor machine working with 100,000 large records might take 2 to 40 minutes to build each model and score all records in 30 seconds per model.**
Model Factor now runs as a cloud based service, which lets users easily upgrade hardware to meet larger loads. A new interface, now in beta, lets end-users manage the modeling process and view the results. Even with the interface, tasks such as exploring poorly performing models take serious data science skills.So it would still be wrong to think of Model Factory as a tool for the unsophisticated. Instead, consider Model Factory as a force multiplier for companies that know
what they’re doing and how to do it, but can’t execute the volumes
required.
Pricing for Model Factory starts at $5,000 per month for modest hardware (4 vCPU/8Gb RAM machine with 500 Gb fast storage). Set-up tasks are covered by an implementation fee, typically around $10,000 to $20,000. Not every company will have the appetite for this sort of system, but those that do may fine Model Factory a welcome addition to their marketing technology smorgasbord.
_____________________________________________________________________________
* For the youngsters: banks used to give away free toasters to attract new customers. This was back, oh, during the 1960’s. I wasn’t there but have heard the stories.
** The exact example provided by the company was: On a 6 vCPU, 64Gb RAM machine, building 500 models on between 20K and 178K records with up to 20,000 variables per record takes an average between 2 and 40 minutes to build each model and 30 seconds per model to score all records. This hardware configuration would cost $12,750 per month.
Saturday, November 28, 2015
Thursday, November 19, 2015
The Big Willow Links Intent Data to Devices to Companies...Another Flavor of Account Based Marketing

What The Big Willow does with intent data is interesting whether it’s the One True ABM or not. The company tracks which devices are consuming what content, associates the content with intent, and then associates the devices - as much as it can - to companies.
The Big Willow uses data from media it serves directly and from the nightly feeds that ad networks and publishers send to media buyers. This tells it which devices saw which content. The system relates the content to intent by parsing it for keywords and phrases related to The Big Willow clients' products and services. Devices are associated with companies using reverse IP lookup for IP addresses registered directly to a specific business. If the IP address belongs to a service provider like Verizon or Comcast, The Big Willow applies a proprietary method that finds the device location based on IP address and infers a match with businesses near that location. That’s far from perfect but can work if there is just one business in a particular industry near that location. What makes this worth the trouble is it can double the number of devices linked to target companies.
The location-based approach clearly has its limits. But it’s important to put those aside and go back to the fact that The Big Willow is tracking consumption by devices, not cookies. This matters because cookies are increasingly ineffective in an era of mobile devices and frequent cookie deletion. It’s also important to bear in mind that The Big Willow is storing consumption of all content for all devices it sees, meaning it can analyze past behavior without advance preparation. This lets it immediately identify prospects who have shown interest in a new client’s industry.
The Big Willow uses this historical data to examine a client’s current marketing automation and CRM databases, distinguishing companies showing intent from those that are inactive, and also finding active companies that are not already in the corporate database. This analysis takes about two weeks to complete. The Big Willow can then target advertising at those audiences, including Web display ads to companies that have not yet visited the client’s own Web site. This extends beyond the usual ABM retargeting of site visitors. Of course, since The Big Willow is capturing intent, it can tailor the ads to the buying stage of each company.
As a final trick, The Big Willow can also track which devices have seen the client’s ads and then use a pixel on the client’s Web site to find which of those devices eventually make a visit. This captures many more connections than the traditional approach of tracking visitors who have clicked on a company ad – which the vast majority of visitors do not.
In short, The Big Willow provides an interesting option for business marketers who want to do intent-based account targeting. It probably won’t be the only tool anyone uses, but it is worth considering it as something to add to your mix. Pricing ranges from $10,000 to $20,000 per month based on specific deliverables and services. The company was founded in 2011 and has dozens of clients.
Monday, November 09, 2015
Predictive Marketing Vendors Look Beyond Lead Scores
It’s clear that 2015 has been the breakout year for predictive analytics in marketing, with at least $242 million in new funding, compared with $376 million in all prior years combined.

But is it possible that predictive is already approaching commodity status? You might think so based on the emergence of open source machine learning like H20 and Google’s announcement today that is it releasing a open source version of its TensorFlow artificial intelligence engine.
Maybe I shouldn't be surprised that predictive marketing vendors seem to have anticipated this. They are, after all, experts at seeing the future. At least, recent announcements make clear that they’re all looking to move past simple model building. I wrote last month about Everstring’s expansion to the world of intent data and account based marketing. The past week brought three more announcements about predictive vendors expanding beyond lead scoring.
Radius kicked off the sequence on November 3 with its announcement of Performance, a dashboard that gives conversion reports on performance of Radius-sourced prospects. What’s significant here is less the reporting than that Radius is moving beyond analytics to give clients lists of potential customers. In particular, its finding new market segments that clients might enter – something different from simply scoring leads that clients present to it or even from finding individual prospects that look like current customers. This isn’t a new service for Radius but it’s one that only some of the other predictive modeling vendors provide.

Radius also recently announced a very nice free offering, the CMO Insights Report. Companies willing to share their Salesforce CRM data can get a report assessing the quality of their CRM records, listing the top five data elements that identify high-value prospects, and suggesting five market segments they might pursue. This is based on combining the CRM data with Radius’ own massive database of information about businesses. It takes zero effort on the marketer’s part and the answer comes back in 24 hours. Needless to say, it’s a great way for Radius to show off its highly automated model building and the extent of its data. I imagine that some companies will be reluctant to sign into Salesforce via the Radius Web site, but if you can get over that hurdle, it’s worth a look.
Infer upped the ante on November 5 with its Prospect Management Platform. This also extends beyond lead scoring to provide access to Infer’s own data about businesses (which it had previously kept to itself) and do several types of artificial intelligence-based recommendations. Like Radius, Infer works by importing the client's CRM data and enhancing it with Infer's information. The system also has connectors to import data from marketing automation and Google Analytics. It then finds prospect segments with above-average sales results, segments that are receiving too much or too little attention from the sales team, and segments with significant changes in other key performance indicators.

Like the Pirate Code, Infer's recommendations are more guidelines than actual rules: it’s up to users to review the findings and decide what, if anything, to do with them. Users who create segments can then have the system automatically track movement of individuals into and out of segments and define actions to take when this occurs. The actions can include sending an alert or creating a task in the CRM system, assigning the lead to a nurture campaign in marketing automation, or using an API to trigger another external action. Infer plans to also recommend the best offer for each group, although this is not in the last week’s release – which is available today to current clients and will be opened to non-customers in early 2016. That last option is an interesting extension in itself, meaning Infer could be used by marketers who have no interest in lead scoring.
Mintigo’s news came today. It included some nice enhancements including a new user interface, account-based lead scores, and lists of high-potential net new accounts. But the really exciting bit was preannouncement of Predictive Campaigns, which is just entering private beta. This is Mintigo’s attempt to build an automated campaign engine that picks the best treatment for each customer in each situation.
 I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.

Conceptually, this is exactly the model I have proposed of “do the right thing, wait, and do the right thing again”. Mintigo’s actual implementation is considerably messier than that, but such is the price of working in the real world. There are still nuances to work out, such as optimizing for long-term value rather than immediate response, incorporating multi-step campaigns, finding efficient testing strategies, automating offer creation. And of course this is just a pre-beta announcement. But, it’s still exciting to see progress past the traditional limits of predefined campaign flows. And, like the other developments this week, it’s a move well beyond basic lead scoring.
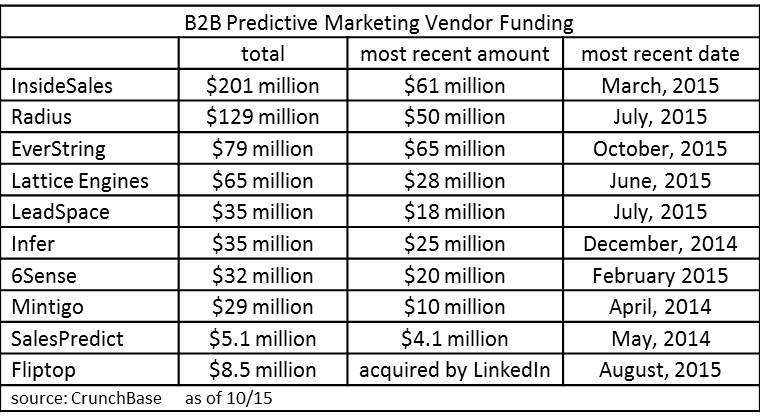
But is it possible that predictive is already approaching commodity status? You might think so based on the emergence of open source machine learning like H20 and Google’s announcement today that is it releasing a open source version of its TensorFlow artificial intelligence engine.
Maybe I shouldn't be surprised that predictive marketing vendors seem to have anticipated this. They are, after all, experts at seeing the future. At least, recent announcements make clear that they’re all looking to move past simple model building. I wrote last month about Everstring’s expansion to the world of intent data and account based marketing. The past week brought three more announcements about predictive vendors expanding beyond lead scoring.
Radius kicked off the sequence on November 3 with its announcement of Performance, a dashboard that gives conversion reports on performance of Radius-sourced prospects. What’s significant here is less the reporting than that Radius is moving beyond analytics to give clients lists of potential customers. In particular, its finding new market segments that clients might enter – something different from simply scoring leads that clients present to it or even from finding individual prospects that look like current customers. This isn’t a new service for Radius but it’s one that only some of the other predictive modeling vendors provide.

Radius also recently announced a very nice free offering, the CMO Insights Report. Companies willing to share their Salesforce CRM data can get a report assessing the quality of their CRM records, listing the top five data elements that identify high-value prospects, and suggesting five market segments they might pursue. This is based on combining the CRM data with Radius’ own massive database of information about businesses. It takes zero effort on the marketer’s part and the answer comes back in 24 hours. Needless to say, it’s a great way for Radius to show off its highly automated model building and the extent of its data. I imagine that some companies will be reluctant to sign into Salesforce via the Radius Web site, but if you can get over that hurdle, it’s worth a look.
Infer upped the ante on November 5 with its Prospect Management Platform. This also extends beyond lead scoring to provide access to Infer’s own data about businesses (which it had previously kept to itself) and do several types of artificial intelligence-based recommendations. Like Radius, Infer works by importing the client's CRM data and enhancing it with Infer's information. The system also has connectors to import data from marketing automation and Google Analytics. It then finds prospect segments with above-average sales results, segments that are receiving too much or too little attention from the sales team, and segments with significant changes in other key performance indicators.

Like the Pirate Code, Infer's recommendations are more guidelines than actual rules: it’s up to users to review the findings and decide what, if anything, to do with them. Users who create segments can then have the system automatically track movement of individuals into and out of segments and define actions to take when this occurs. The actions can include sending an alert or creating a task in the CRM system, assigning the lead to a nurture campaign in marketing automation, or using an API to trigger another external action. Infer plans to also recommend the best offer for each group, although this is not in the last week’s release – which is available today to current clients and will be opened to non-customers in early 2016. That last option is an interesting extension in itself, meaning Infer could be used by marketers who have no interest in lead scoring.
Mintigo’s news came today. It included some nice enhancements including a new user interface, account-based lead scores, and lists of high-potential net new accounts. But the really exciting bit was preannouncement of Predictive Campaigns, which is just entering private beta. This is Mintigo’s attempt to build an automated campaign engine that picks the best treatment for each customer in each situation.
 I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
Conceptually, this is exactly the model I have proposed of “do the right thing, wait, and do the right thing again”. Mintigo’s actual implementation is considerably messier than that, but such is the price of working in the real world. There are still nuances to work out, such as optimizing for long-term value rather than immediate response, incorporating multi-step campaigns, finding efficient testing strategies, automating offer creation. And of course this is just a pre-beta announcement. But, it’s still exciting to see progress past the traditional limits of predefined campaign flows. And, like the other developments this week, it’s a move well beyond basic lead scoring.
Thursday, November 05, 2015
Teradata Plans to Sell Its $200 Million Marketing Application Business. Any Takers?
Teradata today announced it plans to sell its Marketing Applications business. I’ll drop the usual analyst pose of omniscience to admit I didn’t see this coming. It’s only three weeks since Teradata expanded its marketing suite by buying a new Data Management Platform – a move I felt made great sense. They also briefed me at that time on a slew of updates to their other marketing products, demonstrating continued forward movement. There was no clue of a pending sale, although I strongly suspect the people briefing me had no idea it was coming.
According to financial statements within the Teradata announcement, Marketing Applications revenue was down about 9% this year, which is surprising in a generally strong martech market but in line with the rest of Teradata’s business. Teradata told me separately that their marketing cloud business grew 22% year-on-year this quarter, suggesting that the decline came in the older, on-premise products and/or related services. As you may know, Teradata’s marketing applications business was a mashup of Teradata's original, on-premise marketing product, based on the Ceres purchase made 15 years ago and now called Customer Interaction Manger (CIM); the Aprimo cloud-based systems acquired for $525 million in 2010; and several more recent cloud-based acquisitions, notably eCircle email. The Aprimo group was dominant in the years immediately following the acquisition but control shifted back to the older Teradata team more recently. One bit of evidence: the Aprimo brand was dropped in 2013.
Since the original version of this post was written, I've been told by unofficial but reliable sources that Teradata management has said it intends to keep the on-premise CIM business and sell everything else. This makes sense to some degree, since CIM is one of very few enterprise-scale on-premise marketing automation systems. IBM and SAS are really the only other major competitors here, although Oracle and SAP are also contenders. I don’t know how much of Teradata’s revenue comes from CIM or how many new licenses it has sold recently. Based on the information presented above, the business may be shrinking. But there’s definitely strong preference for on-premise marketing automation at many of the large enterprises who are Teradata's primary customers for its database and analytics products (which account for more than 90% of its revenue). So keeping CIM may make sense just as a way to block competitors like IBM and SAS from using their own on-premise marketing automation systems to gain a foothold at Teradata accounts. But it's really hard to imagine any new customers choosing CIM when Teradata has made clear it wants out of the marketing applications business. Even current customers will have to wonder whether Teradata can be relied upon to keep CIM up to date.
So what happens now? Well, Marketing Applications is a $200 million business. Even if CIM generates $50 million of that, which I doubt, the remaining pieces make Teradata a major player in B2C marketing automation. (Point of reference: Salesforce.com reported $505 million revenue for its B2C marketing cloud in 2015.) This suggests that someone will purchase the Teradata systems and continue to sell them.
The question is who that buyer might be. The big enterprise software companies already have their own systems, and CIM would probably the only piece any of them might want (if they wanted to add a stronger on-premise product). It’s conceivable that a private equity firm will purchase the systems and run them more or less independently or combine them with other products – look at HGGC’s recent combination of StrongView and Selligent (in the mid-market) or Zeta Interactive’s purchase of eBay’s CRM systems. If CIM were part of the package, I'd argue that Marketo should buy it and gain true enterprise scale B2C technology while nearly doubling its revenue. But without CIM, that doesn't make much sense.
According to financial statements within the Teradata announcement, Marketing Applications revenue was down about 9% this year, which is surprising in a generally strong martech market but in line with the rest of Teradata’s business. Teradata told me separately that their marketing cloud business grew 22% year-on-year this quarter, suggesting that the decline came in the older, on-premise products and/or related services. As you may know, Teradata’s marketing applications business was a mashup of Teradata's original, on-premise marketing product, based on the Ceres purchase made 15 years ago and now called Customer Interaction Manger (CIM); the Aprimo cloud-based systems acquired for $525 million in 2010; and several more recent cloud-based acquisitions, notably eCircle email. The Aprimo group was dominant in the years immediately following the acquisition but control shifted back to the older Teradata team more recently. One bit of evidence: the Aprimo brand was dropped in 2013.
Since the original version of this post was written, I've been told by unofficial but reliable sources that Teradata management has said it intends to keep the on-premise CIM business and sell everything else. This makes sense to some degree, since CIM is one of very few enterprise-scale on-premise marketing automation systems. IBM and SAS are really the only other major competitors here, although Oracle and SAP are also contenders. I don’t know how much of Teradata’s revenue comes from CIM or how many new licenses it has sold recently. Based on the information presented above, the business may be shrinking. But there’s definitely strong preference for on-premise marketing automation at many of the large enterprises who are Teradata's primary customers for its database and analytics products (which account for more than 90% of its revenue). So keeping CIM may make sense just as a way to block competitors like IBM and SAS from using their own on-premise marketing automation systems to gain a foothold at Teradata accounts. But it's really hard to imagine any new customers choosing CIM when Teradata has made clear it wants out of the marketing applications business. Even current customers will have to wonder whether Teradata can be relied upon to keep CIM up to date.
So what happens now? Well, Marketing Applications is a $200 million business. Even if CIM generates $50 million of that, which I doubt, the remaining pieces make Teradata a major player in B2C marketing automation. (Point of reference: Salesforce.com reported $505 million revenue for its B2C marketing cloud in 2015.) This suggests that someone will purchase the Teradata systems and continue to sell them.
The question is who that buyer might be. The big enterprise software companies already have their own systems, and CIM would probably the only piece any of them might want (if they wanted to add a stronger on-premise product). It’s conceivable that a private equity firm will purchase the systems and run them more or less independently or combine them with other products – look at HGGC’s recent combination of StrongView and Selligent (in the mid-market) or Zeta Interactive’s purchase of eBay’s CRM systems. If CIM were part of the package, I'd argue that Marketo should buy it and gain true enterprise scale B2C technology while nearly doubling its revenue. But without CIM, that doesn't make much sense.
Iterable Offers Mid-Size B2C Marketers Powerful Campaigns in Outbound Channels
As William Shakespeare never wrote, some systems are born with data, some achieve data, and some have data thrust upon them. What the Bard would have meant is that some systems are designed around a marketing database, some add a database later in their development, and some attach to external data. The difference matters because marketers are increasingly required to pick a collection of components that somehow work together to deliver integrated customer experiences. This means that marketers must first determine whether they're looking for a system to provide their primary marketing database (since you only need one of those), and then figure out which products fall into the right category.

Whether you need a system with its own database ultimately depends on whether you have an adequate database in place. Obviously the key word in that sentence is "adequate". How that's defined depends on the situation: key variables include the number and types of data you need available, how quickly new data must be processed, whether source data is already coded with a common customer ID, and how you want other systems to access the data.
As I wrote last week, there are a handful of Customer Data Platforms (CDPs) that do nothing but build a database. Many more systems build a database as part of a larger package that also includes an operational function such as predictive modeling or campaign management. This offers an immediate benefit but it complicates the system choice since you have to judge both the database and the operational features. It’s also trickier in a more subtle way because some systems build a great database but don’t make it fully available to other products. That’s spelled s-i-l-o.
These musings are prompted by my attempt to come to assess Iterable, a product I generally like but find as slippery as one of Shakespeare’s cross-dressing heroines. Iterable definitely builds its own database, using the JSON API and Elasticsearch data store to manage pretty much any kind of data you might throw at it. This can happen in real time (yay!) or via batch file imports. The system even provides its own Javascript tag to post directly from Web pages and emails. It organizes the information into customer profiles that can include both static attributes and events such as transactions. That’s pretty much what you want in your marketing database. Elasticsearch lets the system scale very nicely, returning queries on 100 million+ profiles in seconds. Yay again!
On the other hand, Iterable doesn’t let other systems query the data directly. Users can do analytics and build segments using Iterable’s own tools or export selected elements to other systems in a file. They can also push data to other systems through integration with the Segment data hub. So while Segment might be the core database supporting other marketing systems, Iterable will not. Nor does Iterable do much in the way of identity association: new data must be coded with a customer ID to add it to a profile. This is a pretty common approach so it's not something to hold against Iterable in particular. Just be aware that if you need to solve the association problem, you’ll have to look outside of Iterable for the answer. Fortunately, there are plenty of other specialized systems to do this.
Perhaps Iterable provides so many operational functions that there's no need for other systems to access its data? The answer depends on exactly what functions you need. Iterable provides a flexible segmentation tool that can build static lists and can update dynamic lists in real time as new data is posted. This can be combined with exceptionally powerful multi-step workflows, including rarely-seen features such as converging paths (two nodes can point to the same destination) and parallel streams (the same customer can follow two paths out of the same node). It also supports more common, but still important, functions including filters, splits, a/b tests, waiting periods, API calls to external systems, and sending email, SMS, and push messages. One notably missing feature is predictive modeling to drive personalized messages, but Iterable recently set up an integration with BoomTrain to do this. Iterable still doesn’t offer Web site personalization although it might be able to support that indirectly through BoomTrain, Web hooks, or Segment.
Iterable includes content creation tools for its messaging channels – again, that's email, SMS, and push. This means users must rely on third party software to create forms and landing pages. Nearly all B2B marketing automation systems do have form and page builders, but Iterable is targeted primarily at mid-tier B2C marketers, who are less likely to expect them. Iterable’s B2C focus is further clarified by its prebuilt integration with Magento for ecommerce and with Mixpanel and Google Analytics for mobile and Web analytics. The system also provides a preference center to capture customer permissions to receive messages in different channels – a feature that is essential in B2C, although certainly helpful in B2B as well.
So where does this leave us? Iterable is more powerful than a basic email system but not quite as rich as full-blown marketing automation, let alone an integrated marketing suite or cloud. Page tags, JSON feeds, and Webhooks make it especially good at collecting information, although it will need help with identity association to make full use of this data. It builds powerful outbound campaigns in email, SMS, and mobile apps. Ultimately, this makes it a good choice for mid-size B2C marketers who want to orchestrate outbound messages but are less concerned about Web pages or other inbound channels. Marketers could also use Iterable as the outbound component of a more comprehensive solution with Segment or something similar at the core.
Iterable was founded in 2013 and first released its product about a year ago. It currently has more than 30 clients paying an average around $3,000 per month. List prices start much lower and some clients are much larger.

Whether you need a system with its own database ultimately depends on whether you have an adequate database in place. Obviously the key word in that sentence is "adequate". How that's defined depends on the situation: key variables include the number and types of data you need available, how quickly new data must be processed, whether source data is already coded with a common customer ID, and how you want other systems to access the data.
As I wrote last week, there are a handful of Customer Data Platforms (CDPs) that do nothing but build a database. Many more systems build a database as part of a larger package that also includes an operational function such as predictive modeling or campaign management. This offers an immediate benefit but it complicates the system choice since you have to judge both the database and the operational features. It’s also trickier in a more subtle way because some systems build a great database but don’t make it fully available to other products. That’s spelled s-i-l-o.
These musings are prompted by my attempt to come to assess Iterable, a product I generally like but find as slippery as one of Shakespeare’s cross-dressing heroines. Iterable definitely builds its own database, using the JSON API and Elasticsearch data store to manage pretty much any kind of data you might throw at it. This can happen in real time (yay!) or via batch file imports. The system even provides its own Javascript tag to post directly from Web pages and emails. It organizes the information into customer profiles that can include both static attributes and events such as transactions. That’s pretty much what you want in your marketing database. Elasticsearch lets the system scale very nicely, returning queries on 100 million+ profiles in seconds. Yay again!
On the other hand, Iterable doesn’t let other systems query the data directly. Users can do analytics and build segments using Iterable’s own tools or export selected elements to other systems in a file. They can also push data to other systems through integration with the Segment data hub. So while Segment might be the core database supporting other marketing systems, Iterable will not. Nor does Iterable do much in the way of identity association: new data must be coded with a customer ID to add it to a profile. This is a pretty common approach so it's not something to hold against Iterable in particular. Just be aware that if you need to solve the association problem, you’ll have to look outside of Iterable for the answer. Fortunately, there are plenty of other specialized systems to do this.
Perhaps Iterable provides so many operational functions that there's no need for other systems to access its data? The answer depends on exactly what functions you need. Iterable provides a flexible segmentation tool that can build static lists and can update dynamic lists in real time as new data is posted. This can be combined with exceptionally powerful multi-step workflows, including rarely-seen features such as converging paths (two nodes can point to the same destination) and parallel streams (the same customer can follow two paths out of the same node). It also supports more common, but still important, functions including filters, splits, a/b tests, waiting periods, API calls to external systems, and sending email, SMS, and push messages. One notably missing feature is predictive modeling to drive personalized messages, but Iterable recently set up an integration with BoomTrain to do this. Iterable still doesn’t offer Web site personalization although it might be able to support that indirectly through BoomTrain, Web hooks, or Segment.
Iterable includes content creation tools for its messaging channels – again, that's email, SMS, and push. This means users must rely on third party software to create forms and landing pages. Nearly all B2B marketing automation systems do have form and page builders, but Iterable is targeted primarily at mid-tier B2C marketers, who are less likely to expect them. Iterable’s B2C focus is further clarified by its prebuilt integration with Magento for ecommerce and with Mixpanel and Google Analytics for mobile and Web analytics. The system also provides a preference center to capture customer permissions to receive messages in different channels – a feature that is essential in B2C, although certainly helpful in B2B as well.
So where does this leave us? Iterable is more powerful than a basic email system but not quite as rich as full-blown marketing automation, let alone an integrated marketing suite or cloud. Page tags, JSON feeds, and Webhooks make it especially good at collecting information, although it will need help with identity association to make full use of this data. It builds powerful outbound campaigns in email, SMS, and mobile apps. Ultimately, this makes it a good choice for mid-size B2C marketers who want to orchestrate outbound messages but are less concerned about Web pages or other inbound channels. Marketers could also use Iterable as the outbound component of a more comprehensive solution with Segment or something similar at the core.
Iterable was founded in 2013 and first released its product about a year ago. It currently has more than 30 clients paying an average around $3,000 per month. List prices start much lower and some clients are much larger.
Subscribe to:
Posts (Atom)


