One of the grand challenges facing marketing technology today is having a computer find the best messages to send each customer over time, instead of making marketers schedule the messages in advance. One roadblock has been that automated design requires predicting the long-term impact of each message: just selecting the message with the highest immediate value can reduce future income. This clearly requires optimizing against a metric like lifetime value. But that's really hard to predict.
Coherent Path offers what may be a solution. Using advanced math that I won’t pretend to understand*, they identify offers that lead customers towards higher long-term values. In concrete terms, this often means cross-selling into product categories the customer hasn’t yet purchased. While this isn’t a new tactic, Coherent Path improves it by identifying intermediary products (on the "path" to the target) that the customer is most likely to buy now. It can also optimize other variables such as the time between messages, price discounts, and the balance between long- and short-term results
Coherent Path clients usually start by optimizing their email programs, which offer a good mix of high volume and easy measurability. The approach is to define a promotion calendar, pick product themes for each promotion, and then select the best offers within each theme for each customer. “Themes” are important because they’re what Coherent Path calculates different customers might be interested in. The system relies on marketers to tell it what themes are associated with each product and message (that is, the system has no semantic analytics to do that automatically). But because Coherent Path can predict which customers might buy in which themes, it can suggest themes to include in future promotions.
Lest this seem like the blackest of magic, rest assured that Coherent Path bases its decisions on data. It starts with about two years’ of interactions for most clients, so it can see good sample of customers who have already completed a journey to high value status. Clients need at least several hundred products and preferably thousands. These products need to be grouped into categories so the system can find common patterns among the customer paths. Coherent Path automatically runs tests within promotions to further refine its ability to predict customer behaviors. Most clients also set aside a control group to compare Coherent Path results against customers managed outside the system. Coherent Path reports results such as 22% increase in email revenue and 10:1 return on investment – although of course your mileage may vary.
The system can manage other channels than email. Coherent Path says most of its clients move on to display ads, which are also relatively easy to target and measure. Web site offers usually come next.
Coherent Path was founded in 2012 and has been offering its current product for more than two years. Clients are mostly mid-size and large retailers, including Neiman Marcus, L.L. Bean, and Staples. Pricing starts around $10,000 per month.
_________________________________________________________________________
* Download their marketing explanation here or read an academic discussion here.
Showing posts with label predictive analytics. Show all posts
Showing posts with label predictive analytics. Show all posts
Wednesday, May 24, 2017
Wednesday, August 24, 2016
ABM Vendor Guide: Features to Look for in Target Scoring Vendors
My last post used data from our new Guide to ABM Vendors to describe differentiators among companies that provide external data for account based marketing. Let’s continue the series by looking at differentiators related to Target Scoring, the second sub-function related to the ABM process of identifying target accounts.
While External Data is one of the broadest sub-functions described in the Guide, Target Scoring is one of the narrowest. Target Scoring isn’t just any use of predictive analytics, which can also include things like finding surges in content consumption (used to identify intent) or recommending the best content to send an individual. As the Guide defines it:
Vendors in this category use statistical techniques to select target accounts. The models most often predict whether an account will make a purchase, but sometimes predict events such as renewing a contract or becoming an opportunity in the sales pipeline. Scores can be built for individuals as well as accounts, although account scores are most important for ABM. Many scoring vendors gather external data from public or commercial sources (or both) to gain more inputs for their models. They may or may not share this data with their clients, and they may or may not provide net new records. Target scoring is more than tracking intent surges, which do not capture other factors that contribute to likelihood of purchase.
The vendors in this category include the specialized scoring firms (Infer, Lattice Engines, Leadspace, Mintigo, Radius) plus companies that do scoring as part of a data offering (Avention, Datanyze, Dun & Bradstreet, InsideView, GrowthIntel) or for message targeting (Demandbase, Everstring, Evergage, Mariana, MRP, The Big Willow). Beyond those fundamental differences in the vendor businesses, specific differentiators include:
|
ABM Process
|
System Function
|
Sub-Function
|
Number of
Vendors
|
|
Identify Target Accounts
|
Assemble Data
|
External Data
|
28
|
|
Select Targets
|
Target Scoring
|
15
|
|
|
Plan Interactions
|
Assemble Messages
|
Customized Messages
|
6
|
|
Select Messages
|
State-Based Flows
|
10
|
|
|
Execute Interactions
|
Deliver Messages
|
Execution
|
19
|
|
Analyze Results
|
Reporting
|
Result Analysis
|
16
|
While External Data is one of the broadest sub-functions described in the Guide, Target Scoring is one of the narrowest. Target Scoring isn’t just any use of predictive analytics, which can also include things like finding surges in content consumption (used to identify intent) or recommending the best content to send an individual. As the Guide defines it:
Vendors in this category use statistical techniques to select target accounts. The models most often predict whether an account will make a purchase, but sometimes predict events such as renewing a contract or becoming an opportunity in the sales pipeline. Scores can be built for individuals as well as accounts, although account scores are most important for ABM. Many scoring vendors gather external data from public or commercial sources (or both) to gain more inputs for their models. They may or may not share this data with their clients, and they may or may not provide net new records. Target scoring is more than tracking intent surges, which do not capture other factors that contribute to likelihood of purchase.
The vendors in this category include the specialized scoring firms (Infer, Lattice Engines, Leadspace, Mintigo, Radius) plus companies that do scoring as part of a data offering (Avention, Datanyze, Dun & Bradstreet, InsideView, GrowthIntel) or for message targeting (Demandbase, Everstring, Evergage, Mariana, MRP, The Big Willow). Beyond those fundamental differences in the vendor businesses, specific differentiators include:
- the range of data used to build models, including which data types and how much is proprietary to the vendor
- amount of client data (if any) loaded into the system and retained after models are built
- advanced matching of unaffiliated leads to accounts (an important part of preparing data for account-level modeling)
- tracking movement of accounts and contacts through different segments over time (as opposed to simply providing scores or target lists on demand)
- self-service model building (as opposed to relying on vendor staff to build models for clients)
- separate fit, engagement, and intent scores (as opposed to a single over-all score)
- range of model types created (fit, engagement, behavior, product affinity, content consumption, etc.)
- limits on number of models included in the base fee
- implementation time (for the first model) and model creation time (for subsequent models
- sales advisory outputs including talking points, intent indicators, product recommendations, content suggestions, etc.
Wednesday, January 20, 2016
True Influence InsightBASE Simplifies Use of B2B Intent Data
Intent data is one of hottest topics in marketing today – see, for example, Oracle’s recent purchase of AddThis. But while the promise of intent data is irresistible – “reach prospects with demonstrated interest in your product!” – the reality has been less appealing. Even setting aside issues of accuracy and coverage, there are problems with both advertising and email, the two primary applications for intent data. Advertising can reach large numbers of people but just a tiny fraction will click on an ad and a tiny fraction of those will provide contact information. Intent-based email lists are obviously contactable but volumes are often quite low.
B2B lead generation vendor True Influence today announced a new product to help fill these gaps. InsightBASE monitors intent signals – in the form of visits to Web pages with relevant content – and notifies clients when there is surge in activity for companies on a target list. The notifications can be loaded as lists into a marketing automation or CRM system, where they can trigger advertising, sales calls, or other actions. Clients also receive contact names, email addresses, and phone numbers at those companies. The contact data is drawn from True Influence’s master list of 30 million business contacts, which are continuously verified to ensure deliverability. Although the names are not tied directly to Web visits, they are selected by job title and level, so they should be appropriate. Visits are tied to companies based on the user’s Web domain – a typical approach although one that can’t misses many sessions from home offices and mobile devices.
So, what distinguishes InsightBASE from other intent-based products? The main difference is that users get the company and contact lists. This contrasts with many intent-based advertising vendors, who serve ads to qualified audiences but don't tell clients exactly whom they’re reaching. InsightBASE also differs from predictive marketing vendors who use intent data as inputs to their scoring systems and in some cases also provide lead lists: although predictive models almost surely do a better job of isolating the best prospects than InsightBASE’s simple profiles plus surge tracking, the models add considerable cost and complexity.
True Influence also says its partner network gives it access to more intent data than anyone else. That's possible but I haven’t done the research to confirm it. Nor is it necessarily important, since activities on some Web sites are less significant than others. The value of data from True Influence, or anyone else, can only be resolved through tests, which will probably give different results for different purposes.
The mechanics of InsightBASE are straightforward. Users set up a campaign by either uploading their own list of target companies or making selections from True Influence’s own database of more than three million Web domains. Selections can use standard filters such as industry, location, number of employees, or domain type (such as .edu or .gov). They can also be based on use of specific technologies, allowing marketers to target competitors’ customers. The next step is to specify keywords to use as indicators of intent. True Influence has its own list of about 5,000 keywords and uses them to do its own classification of Web pages. It can add new keywords as needed. Finally, InsightBASE runs a report showing how many of the target companies visited pages with the specified keywords over the past thirty days, and whether their activity increased, decreased, or remained the same compared with previous periods. This gives a good indication of the potential volume of future activity.
Once the campaign begins, users can extract lists of domains that exceeded a specified activity level or had change in activity. They can export the domains, contacts associated with the domains, or both. InsightBASE has standard integrations with Marketo, Oracle Eloqua, and Salesforce.com. Once the lists are loaded into those systems, they can be used for email, advertising, sales calls, or other purposes.
Pricing for InsightBASE is based on the number of domains monitored, starting at $2,500 per month for 2,500 domains with discounts for higher volumes. There are no separate fees for additional campaigns, contact names, or supporting services. True Influence reports that its initial tests showed companies with activity surges responded to promotion emails at four times the rate of non-targeted companies.
B2B lead generation vendor True Influence today announced a new product to help fill these gaps. InsightBASE monitors intent signals – in the form of visits to Web pages with relevant content – and notifies clients when there is surge in activity for companies on a target list. The notifications can be loaded as lists into a marketing automation or CRM system, where they can trigger advertising, sales calls, or other actions. Clients also receive contact names, email addresses, and phone numbers at those companies. The contact data is drawn from True Influence’s master list of 30 million business contacts, which are continuously verified to ensure deliverability. Although the names are not tied directly to Web visits, they are selected by job title and level, so they should be appropriate. Visits are tied to companies based on the user’s Web domain – a typical approach although one that can’t misses many sessions from home offices and mobile devices.
So, what distinguishes InsightBASE from other intent-based products? The main difference is that users get the company and contact lists. This contrasts with many intent-based advertising vendors, who serve ads to qualified audiences but don't tell clients exactly whom they’re reaching. InsightBASE also differs from predictive marketing vendors who use intent data as inputs to their scoring systems and in some cases also provide lead lists: although predictive models almost surely do a better job of isolating the best prospects than InsightBASE’s simple profiles plus surge tracking, the models add considerable cost and complexity.
True Influence also says its partner network gives it access to more intent data than anyone else. That's possible but I haven’t done the research to confirm it. Nor is it necessarily important, since activities on some Web sites are less significant than others. The value of data from True Influence, or anyone else, can only be resolved through tests, which will probably give different results for different purposes.
The mechanics of InsightBASE are straightforward. Users set up a campaign by either uploading their own list of target companies or making selections from True Influence’s own database of more than three million Web domains. Selections can use standard filters such as industry, location, number of employees, or domain type (such as .edu or .gov). They can also be based on use of specific technologies, allowing marketers to target competitors’ customers. The next step is to specify keywords to use as indicators of intent. True Influence has its own list of about 5,000 keywords and uses them to do its own classification of Web pages. It can add new keywords as needed. Finally, InsightBASE runs a report showing how many of the target companies visited pages with the specified keywords over the past thirty days, and whether their activity increased, decreased, or remained the same compared with previous periods. This gives a good indication of the potential volume of future activity.
Once the campaign begins, users can extract lists of domains that exceeded a specified activity level or had change in activity. They can export the domains, contacts associated with the domains, or both. InsightBASE has standard integrations with Marketo, Oracle Eloqua, and Salesforce.com. Once the lists are loaded into those systems, they can be used for email, advertising, sales calls, or other purposes.
Pricing for InsightBASE is based on the number of domains monitored, starting at $2,500 per month for 2,500 domains with discounts for higher volumes. There are no separate fees for additional campaigns, contact names, or supporting services. True Influence reports that its initial tests showed companies with activity surges responded to promotion emails at four times the rate of non-targeted companies.
Monday, November 09, 2015
Predictive Marketing Vendors Look Beyond Lead Scores
It’s clear that 2015 has been the breakout year for predictive analytics in marketing, with at least $242 million in new funding, compared with $376 million in all prior years combined.

But is it possible that predictive is already approaching commodity status? You might think so based on the emergence of open source machine learning like H20 and Google’s announcement today that is it releasing a open source version of its TensorFlow artificial intelligence engine.
Maybe I shouldn't be surprised that predictive marketing vendors seem to have anticipated this. They are, after all, experts at seeing the future. At least, recent announcements make clear that they’re all looking to move past simple model building. I wrote last month about Everstring’s expansion to the world of intent data and account based marketing. The past week brought three more announcements about predictive vendors expanding beyond lead scoring.
Radius kicked off the sequence on November 3 with its announcement of Performance, a dashboard that gives conversion reports on performance of Radius-sourced prospects. What’s significant here is less the reporting than that Radius is moving beyond analytics to give clients lists of potential customers. In particular, its finding new market segments that clients might enter – something different from simply scoring leads that clients present to it or even from finding individual prospects that look like current customers. This isn’t a new service for Radius but it’s one that only some of the other predictive modeling vendors provide.

Radius also recently announced a very nice free offering, the CMO Insights Report. Companies willing to share their Salesforce CRM data can get a report assessing the quality of their CRM records, listing the top five data elements that identify high-value prospects, and suggesting five market segments they might pursue. This is based on combining the CRM data with Radius’ own massive database of information about businesses. It takes zero effort on the marketer’s part and the answer comes back in 24 hours. Needless to say, it’s a great way for Radius to show off its highly automated model building and the extent of its data. I imagine that some companies will be reluctant to sign into Salesforce via the Radius Web site, but if you can get over that hurdle, it’s worth a look.
Infer upped the ante on November 5 with its Prospect Management Platform. This also extends beyond lead scoring to provide access to Infer’s own data about businesses (which it had previously kept to itself) and do several types of artificial intelligence-based recommendations. Like Radius, Infer works by importing the client's CRM data and enhancing it with Infer's information. The system also has connectors to import data from marketing automation and Google Analytics. It then finds prospect segments with above-average sales results, segments that are receiving too much or too little attention from the sales team, and segments with significant changes in other key performance indicators.

Like the Pirate Code, Infer's recommendations are more guidelines than actual rules: it’s up to users to review the findings and decide what, if anything, to do with them. Users who create segments can then have the system automatically track movement of individuals into and out of segments and define actions to take when this occurs. The actions can include sending an alert or creating a task in the CRM system, assigning the lead to a nurture campaign in marketing automation, or using an API to trigger another external action. Infer plans to also recommend the best offer for each group, although this is not in the last week’s release – which is available today to current clients and will be opened to non-customers in early 2016. That last option is an interesting extension in itself, meaning Infer could be used by marketers who have no interest in lead scoring.
Mintigo’s news came today. It included some nice enhancements including a new user interface, account-based lead scores, and lists of high-potential net new accounts. But the really exciting bit was preannouncement of Predictive Campaigns, which is just entering private beta. This is Mintigo’s attempt to build an automated campaign engine that picks the best treatment for each customer in each situation.
 I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.

Conceptually, this is exactly the model I have proposed of “do the right thing, wait, and do the right thing again”. Mintigo’s actual implementation is considerably messier than that, but such is the price of working in the real world. There are still nuances to work out, such as optimizing for long-term value rather than immediate response, incorporating multi-step campaigns, finding efficient testing strategies, automating offer creation. And of course this is just a pre-beta announcement. But, it’s still exciting to see progress past the traditional limits of predefined campaign flows. And, like the other developments this week, it’s a move well beyond basic lead scoring.
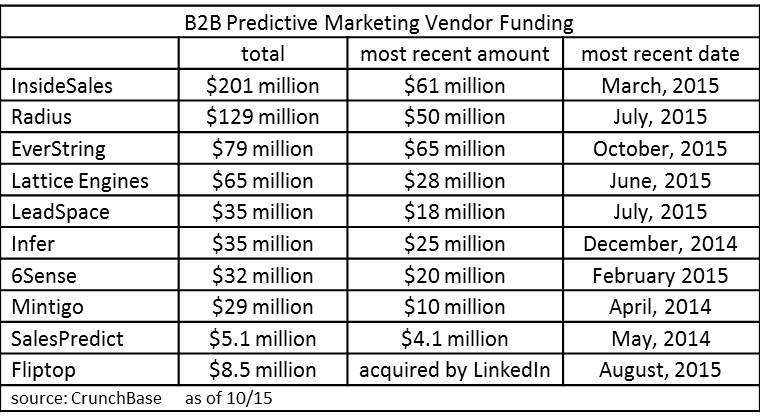
But is it possible that predictive is already approaching commodity status? You might think so based on the emergence of open source machine learning like H20 and Google’s announcement today that is it releasing a open source version of its TensorFlow artificial intelligence engine.
Maybe I shouldn't be surprised that predictive marketing vendors seem to have anticipated this. They are, after all, experts at seeing the future. At least, recent announcements make clear that they’re all looking to move past simple model building. I wrote last month about Everstring’s expansion to the world of intent data and account based marketing. The past week brought three more announcements about predictive vendors expanding beyond lead scoring.
Radius kicked off the sequence on November 3 with its announcement of Performance, a dashboard that gives conversion reports on performance of Radius-sourced prospects. What’s significant here is less the reporting than that Radius is moving beyond analytics to give clients lists of potential customers. In particular, its finding new market segments that clients might enter – something different from simply scoring leads that clients present to it or even from finding individual prospects that look like current customers. This isn’t a new service for Radius but it’s one that only some of the other predictive modeling vendors provide.

Radius also recently announced a very nice free offering, the CMO Insights Report. Companies willing to share their Salesforce CRM data can get a report assessing the quality of their CRM records, listing the top five data elements that identify high-value prospects, and suggesting five market segments they might pursue. This is based on combining the CRM data with Radius’ own massive database of information about businesses. It takes zero effort on the marketer’s part and the answer comes back in 24 hours. Needless to say, it’s a great way for Radius to show off its highly automated model building and the extent of its data. I imagine that some companies will be reluctant to sign into Salesforce via the Radius Web site, but if you can get over that hurdle, it’s worth a look.
Infer upped the ante on November 5 with its Prospect Management Platform. This also extends beyond lead scoring to provide access to Infer’s own data about businesses (which it had previously kept to itself) and do several types of artificial intelligence-based recommendations. Like Radius, Infer works by importing the client's CRM data and enhancing it with Infer's information. The system also has connectors to import data from marketing automation and Google Analytics. It then finds prospect segments with above-average sales results, segments that are receiving too much or too little attention from the sales team, and segments with significant changes in other key performance indicators.

Like the Pirate Code, Infer's recommendations are more guidelines than actual rules: it’s up to users to review the findings and decide what, if anything, to do with them. Users who create segments can then have the system automatically track movement of individuals into and out of segments and define actions to take when this occurs. The actions can include sending an alert or creating a task in the CRM system, assigning the lead to a nurture campaign in marketing automation, or using an API to trigger another external action. Infer plans to also recommend the best offer for each group, although this is not in the last week’s release – which is available today to current clients and will be opened to non-customers in early 2016. That last option is an interesting extension in itself, meaning Infer could be used by marketers who have no interest in lead scoring.
Mintigo’s news came today. It included some nice enhancements including a new user interface, account-based lead scores, and lists of high-potential net new accounts. But the really exciting bit was preannouncement of Predictive Campaigns, which is just entering private beta. This is Mintigo’s attempt to build an automated campaign engine that picks the best treatment for each customer in each situation.
 I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
I've written about this sort of thing many times, as recently as this July and as far back as 2013. Mintigo’s approach is to first instrument the client’s marketing efforts across all channels to track promotion response; then run automated a/b tests to see how each offer performs in different channels for different prospects; use the results to build automated, self-adjusting predictive response models; and then set up a process to automatically select the best offer, channel, and message timing for each customer, execute it, wait for response, and repeat the cycle. Execution happens by setting up separate marketing automation campaigns for the different offers. These campaigns execute Mintigo’s instructions for the right channel and timing for each prospect, capture the response, and alert Mintigo to start again. The initial deployment is limited to Oracle Eloqua, which had the best APIs for the purpose, although Mintigo plans to add other marketing automation partners in the future.
Conceptually, this is exactly the model I have proposed of “do the right thing, wait, and do the right thing again”. Mintigo’s actual implementation is considerably messier than that, but such is the price of working in the real world. There are still nuances to work out, such as optimizing for long-term value rather than immediate response, incorporating multi-step campaigns, finding efficient testing strategies, automating offer creation. And of course this is just a pre-beta announcement. But, it’s still exciting to see progress past the traditional limits of predefined campaign flows. And, like the other developments this week, it’s a move well beyond basic lead scoring.
Friday, October 23, 2015
Why Time Is the Real Barrier to Marketing Technology Adoption and What To Do About It

- Sailthru introducing its next round of predictive modeling and personalization features and working to help users adopt them. As you probably don’t know, Sailthru automatically creates several scores on each customer record for things such as likelihood to purchase in the next week and likelihood to opt out of email. The company is making those available to guide list selection and content personalization for both email and Web pages. One big focus at the conference was getting more clients to use them.
- Yours Truly presenting to the Sailthru attendees about building better data. The thrust was that marketers know they need better data but still don’t give it priority. I tried to get them so excited with use cases – a.k.a. “business porn” – that they’d decide it was more important than other projects. If they wanted it badly enough, the theory went, they’d find the time and budget for the necessary technology and training. I probably shouldn’t admit this, but I was so determined to keep their attention that I resorted to a bar chart built entirely of kittens. To download the deck, kittens and all, click here.
- Various experts at Marketing Profs talking (mostly over drinks) about the growth of Account Based Marketing. The consensus was that ABM is still in the early stages where people don’t agree on what’s included or how to evaluate results. Specific questions included whether ABM should deliver actual prospect names (at the risk of being measured solely on cost per lead); what measurements really do make sense (and whether marketers will pay for measurement separately from the ABM system); and how to extend ABM beyond display ad targeting. Or at least I think that’s what we discussed; the room was loud and drinks were free.
- Me (again) advising Marketing Profs attendees on avoiding common mistakes when selecting a marketing automation vendor. My message here, repeated so many times it may have been annoying, was that users MUST MUST MUST define specific requirements and explore vendor features in detail to pick the right system. One epiphany was finding that nearly everyone in the room already had a marketing automation product in place – something that would not have been true two or three years ago. These are knowledgeable buyers, which changes things completely. (Click here for those slides which had no kittens but do include a nice unicorn.)
You may have noticed a common theme in these moments: trying to help marketers do things that are clearly in their interest but they're somehow avoiding. Making fuller use of predictive models, building a complete customer view, focusing on target accounts, and using relevant system selection criteria are all things marketers know they should do. Yet nearly all industry discussion is focused on proving their value once again, or – usually the next step – in explaining how to do it.
What's the real obstacle? Surveys often show that budget, strategy, or technology are the barriers. (See ChiefMartec Scott Brinker's recent post for more on this topic.) But when you ask marketers face to face about the obstacles, the reason that comes up is consistently lack of time. (My theory on the difference is that people pressed for time don’t answer surveys.) And time, as I hinted above, is really a matter of priority: they are spending their time on other things that seem more important.
So the way to get marketers to do new things is to convince them they are worth the time. That is, you must convince them the new things are more important than their current priorities. Alternately, you can make the new thing so easy that it doesn’t need any time at all. The ABM vendors I discussed this with – all highly successful marketers – were doing both of these already, although they were polite enough not to roll their eye and say “duh” when I brought it up.
How do you convince marketers (or any other buyers) that something they already know is important is more important than whatever they’re doing now? I’d argue this isn’t likely to be a rational choice: MAYBE you can find some fabulously compelling proof of value, but the marketers will probably have seen those arguments already and not been convinced. More likely, you'll need to rely on emotion. This means getting marketers excited about doing something (that’s where the “business porn” comes in) or scared about the consequences of not doing it (see the CEB Challenger Sales model, for example). In short, it’s about appealing to basic instincts – what Seth Godin calls the lizard brain – which will ultimately dictate to the rational mind.
What about the other path I mentioned around the time barrier, showing that the new idea takes so little time that it doesn’t require giving up any current priorities? That’s a more rational argument, since you have to convince the buyer that it’s true. But everything new will take up at least some time and money, so there’s still some need to get the buyer excited enough to make the extra effort. This brings us back to the lizard.
I’m not saying all marketing should be emotional. Powerful as they are, emotions can only tip the balance if the rational choice is close. And I’m talking about the specific situation of getting people to adopt something new, which is quite different from, say, selling an existing solution against a similar competitor. But I spend a lot of time talking with vendors who are selling new types of solutions and talking with marketers who would benefit from those solutions. Both the vendors and I often forget that time, not budget, skills or value, is the real barrier to adoption and that emotions are the key to unlocking more time. So emotions must be a big part of our marketing if we, and the marketers we're trying to serve, are ultimately going to succeed.
Thursday, August 27, 2015
LinkedIn Buys Fliptop: Why Account Based Marketing and Predictive Analytics Are a Natural Fit

The original inspiration for the planned post was a set of three back-to-back conversations I had last Friday with one ABM vendor and two predictive analytics companies (none of which were Fliptop or LinkedIn). The juxtaposition highlighted just how much predictive and ABM complement each other. In fact, the relationship is so obvious that it almost seems unnecessary to lay it out: predictive vendors help marketers find accounts to target; ABM helps marketers reach target accounts. You can safely assume that both sets of vendors have noticed the relationship and that many are working to combine the two techniques. The Fliptop/LinkedIn deal is just more evidence of the connection.
To move past the very obvious, ABM vendors – whose basic business is selling ads targeted to specific companies – could also use predictive analytics to refine their ad targeting. This could mean selecting the best people to reach within targeted accounts or selecting the most effective ad placements to reach those accounts. This requires integration of predictive analytics within the ABM product, not just using predictive before ABM begins. I expect LinkedIn will use Fliptop's capabilities in these ways among others.
But, getting back to last week's conversations, what really struck me was a less obvious connection of ABM and predictive to content. Two of the vendors described using their systems to select which content to send to specific accounts or individuals. These selections are based on previous behavior, something that certainly makes sense. But I don't generally recall hearing ABM or predictive vendors discussing as one of their applications. It's an important idea because it promises to improve results by delivering more relevant content for the same price. The same data gives marketers insights into broader trends in the types of content that buyers find interesting.
Content analysis requires the ABM or predictive system to be aware of the topics of the content being consumed. This is only possible if someone specifically goes to the trouble of tagging the content and capturing the tags. So content analysis is not quite a natural byproduct of the ABM or predictive analytics: it takes some intentional effort. A corollary is that not all ABM and predictive systems can deliver this benefit. So it's something to specifically ask prospective vendors about if you think you'll want it.
To put things in a still broader perspective, targeting content with ABM and predictive systems is part of a broader trend of using advanced technology to help marketers create, manage, and optimize content. This is something that vendors like Captora, Persado, and Olapic do in terms of content creation, and Jivox, OneSpot, Triblio, and BloomReach do in terms of personalized content creation. I've been looking at a lot of those systems recently although I haven't written much about them here. New targeting technologies create unprecedented demands for more content, which only new content technologies can meet. So you can expect to hear more about technology-based content creation, whether I write about it or not.
Friday, July 17, 2015
Predictive Analytics: Should Automated Content Selection Work by Segment or Individual?
 Two vendors made the same point with me this week, which is reason enough for a blog post in mid-July. The point was the difference between basing content selection on individuals and on segments. I have never considered the distinction to be especially important, since segment membership is determined by individual behaviors and individual-level decisions are guided by behavior patterns of groups. But the two vendors in question (Evergage and Jetlore) and another I spoke with earlier (Sailthru) were downright religious about the superiority of their approach (individual-level selections in every case). So I thought it worth some discussion.
Two vendors made the same point with me this week, which is reason enough for a blog post in mid-July. The point was the difference between basing content selection on individuals and on segments. I have never considered the distinction to be especially important, since segment membership is determined by individual behaviors and individual-level decisions are guided by behavior patterns of groups. But the two vendors in question (Evergage and Jetlore) and another I spoke with earlier (Sailthru) were downright religious about the superiority of their approach (individual-level selections in every case). So I thought it worth some discussion.First, let’s clarify the topic. The distinction these vendors were making is between selecting content separately for each individual and selecting the same content for all members of a segment. Of course, customers are assigned to segments based on their individual behavior and other attributes, but once someone is in a segment, the segment-based system ignores individual differences. Among segment-based systems, collaborative filtering uses product selections almost exclusively: this is the classic “customers who looked at this product also considered these products” approach, which doesn’t take into account other aspects of the customer’s history. Other methods build segments based on customer life stage, demographics, and similar broad attributes. It’s possible to build segments based on very detailed behavioral differences, but that’s likely to create too many segments to be practical.
At an operational level, the individual-level systems use automated analytics to rank all possible content choices for each individual using that individual’s data. Segment-based systems either use rules to select content for each segment or use automated analytics to rank content choices for the segment as a whole. The individual-level approach makes the most sense when there are many content choices to consider, as with retail merchandise or entertainment (books, music, movies, etc.). Those are cases where getting precisely the right content in front of the customer is much more effective than offering everyone the most commonly-selected items. Retail and entertainment marketers also usually have detailed history which supports accurate predictions of what the customer will want. Segment-based systems work best when only a few choices are available. This means a separate segment can be created for each item or, more realistically, segments come first and items are created to serve them.
So does the entire debate really come down to using individual-level systems when there are lots of choices and segment-based systems when there are only a few? Not really: collaborative filtering can also handle massive numbers of options with great accuracy. The difference is that collaborative filtering doesn’t really consider much beyond a particular product choice, while a sophisticated individual-level system will consider other factors including the current context and the customer’s history. Done correctly, this should yield more appropriate selections. On the other hand, individual-level approaches require more data and more complex analytics, so there will be cases where a segment-based method is ultimately more appropriate.
Moreover, the two approaches are as much complementary as competitive. A segment can indicate customer state, such as just-acquired, satisfied, or churn-risk, which constrains the contents considered for offer by the individual-level system.* Or a segment-level system could chose the type of message to send but let the individual-level system pick the specific contents. Dynamic content within email campaigns often works exactly this way.
In fact, I’d argue that state-based segmentation is essential for individual-level optimization because states provide a framework to organize the masses of detailed customer data. Without tagging the customer’s current state during each event, it would be very difficult for even the most sophisticated analytical system to see the larger arc of the customer life cycle or to understand the relationship between specific offers and long-term outcomes.
All this has practical implications for marketers considering these systems.
- for individual-level systems, make sure they can look beyond predicting the highest immediate response rate to measuring impact on long-term objectives such as conversion or lifetime value.
- for segment-level systems, make sure they can take into account the customer’s past behaviors and attributes, not just the products they have recently purchased or considered
- for all types of systems, assess how they track and guide the customer through the stages of her long-term journey
You'll want to consider other differences between content selection systems, such as number of items they can manage, how quickly they return selections, how they incorporate items without a sales history, and what data they consider in their analysis. Just remember that making selections isn’t an end in itself: you want to make choices that will create the greatest long-term value. To do that, it’s not a choice between individual and segment level analysis. You need both.
____________________________________________________________________________
* See my June 25 post for a more detailed discussion of state-based campaigns.
Thursday, June 11, 2015
Highspot Sales Enablement Helps Sales People Find Content and Marketers Measure What Works
“Sales enablement” is something of a catch-all term for a wide range of solutions that help sales people do their jobs better. Highspot has staked out the corner of this world occupied by systems that help sales people find the right marketing materials. It grew out of the pain that co-founder Robert Wahbe felt which running marketing for Microsoft’s Server and Tools Division, where he found no good tools to help sales people and channel partners find the right materials when they needed them.
When Highspot was founded in 2012, it focused on better content discovery for sales people. But the firm soon learned that this wasn’t enough. It has now redefined its core mission as improving results by showing which content is working. This is currently measured by tracking how often each item is used by sales people and read by recipients. The July release will supplement this with opportunity information from Salesforce.com CRM, allowing correlation of content usage with funnel stage conversions and revenue.
Highspot mostly does what you’d expect from this sort of system: it lets users load content and sales people, tracks who sends which content to which prospects, and reports on results. Users can set up collections (called “spots”) of materials for a particular product, sales team, funnel stage, region, or any other purpose. They can find content by looking in a spot, by filtering on sales stage, industry, product, and other attributes, or by doing an “intelligent semantic search” that recommends content based on past choices by the user and others. Users can view, download, bookmark or email the selected content or do a live pitch to a prospect. The system automatically adds pitches and emails to the prospect history in Salesforce. It can also track when a piece of emailed content is opened by the prospect, how long they kept it open, and which pages they viewed. A dashboard can highlight new and featured content. The system will also analyze the inventory of available contents to find gaps or redundancies by sales stage, product, region, etc.
The operational details are all nicely executed, which is probably the most important consideration for a sales enablement system: if it's not easy, sales people won’t use it. But from a technology standpoint, what’s most interesting about Highspot is what the vendor calls “content genomics”. This uses machine learning to examine each piece of content – such as each slide in a Powerpoint deck – and identify properties including text, color, graphs, and images. Different pieces are then compared to find similarities and grouped into “content families”. This approach lets Highspot recognize when a piece has been modified and reused, for example by taking a slide from one deck and adding it to another with some reformatting along the way. Identifying these relationships gives a much more accurate understanding of how often each item is used and how well it is performing. Without this grouping, results from the system could be highly misleading.
Highspot now has more than 100 paying customers. The system is now sold primarily to marketing departments as the system of record for marketing content. There’s a limited function Business Edition and a full function Enterprise Edition, which includes Salesforce integration. Pricing for the Enterprise Edition isn’t published but the vendor says that, once volume discounts are included, it is usually less than the $30 per month per user charged for the Business Edition.
When Highspot was founded in 2012, it focused on better content discovery for sales people. But the firm soon learned that this wasn’t enough. It has now redefined its core mission as improving results by showing which content is working. This is currently measured by tracking how often each item is used by sales people and read by recipients. The July release will supplement this with opportunity information from Salesforce.com CRM, allowing correlation of content usage with funnel stage conversions and revenue.
Highspot mostly does what you’d expect from this sort of system: it lets users load content and sales people, tracks who sends which content to which prospects, and reports on results. Users can set up collections (called “spots”) of materials for a particular product, sales team, funnel stage, region, or any other purpose. They can find content by looking in a spot, by filtering on sales stage, industry, product, and other attributes, or by doing an “intelligent semantic search” that recommends content based on past choices by the user and others. Users can view, download, bookmark or email the selected content or do a live pitch to a prospect. The system automatically adds pitches and emails to the prospect history in Salesforce. It can also track when a piece of emailed content is opened by the prospect, how long they kept it open, and which pages they viewed. A dashboard can highlight new and featured content. The system will also analyze the inventory of available contents to find gaps or redundancies by sales stage, product, region, etc.
The operational details are all nicely executed, which is probably the most important consideration for a sales enablement system: if it's not easy, sales people won’t use it. But from a technology standpoint, what’s most interesting about Highspot is what the vendor calls “content genomics”. This uses machine learning to examine each piece of content – such as each slide in a Powerpoint deck – and identify properties including text, color, graphs, and images. Different pieces are then compared to find similarities and grouped into “content families”. This approach lets Highspot recognize when a piece has been modified and reused, for example by taking a slide from one deck and adding it to another with some reformatting along the way. Identifying these relationships gives a much more accurate understanding of how often each item is used and how well it is performing. Without this grouping, results from the system could be highly misleading.
Highspot now has more than 100 paying customers. The system is now sold primarily to marketing departments as the system of record for marketing content. There’s a limited function Business Edition and a full function Enterprise Edition, which includes Salesforce integration. Pricing for the Enterprise Edition isn’t published but the vendor says that, once volume discounts are included, it is usually less than the $30 per month per user charged for the Business Edition.
Tuesday, June 02, 2015
Blueshift Offers a Simple B2C Customer Data Platform
[Note: this post is from 2015. Click here for a newer post about BlueShift.]
It’s just over two years since I started writing about Customer Data Platforms. One thing that’s become clear since then is that only big companies will purchase a marketing database by itself. Everyone else wants to combine the database with a practical application. B2B CDPs have favored analytical applications like lead scores and churn predictions. B2C CDPs have often included campaign engines that manage triggers, query-based segmentations, and multi-step program flows in addition to predictive models. But even the B2C CDPs rely on external systems such as email agents and Web content managers to deliver the campaign messages.
Blueshift fits nicely into the B2C CDP mold: it builds a multisource database, incorporates machine learning-based predictive models, uses filters to create segments, and runs multi-step campaigns that are executed by external systems in email, SMS, mobile apps, and display and Facebook retargeting. What sets Blueshift apart – and this is typical of later entrants to a new market – are a lower price point and simpler operation than early B2C CDPs like RedPoint and AgilOne.
How low? Pricing for the most basic version of Blueshift starts at $999 per month. The most advanced version starts at $3,999 per month for all features and up to 1 million “active users” across all channels. (The company says that most clients are in fact larger than one million users, with the largest at 100 million.) The fact that prices are published is itself a mark of a later entrant.
How simple? Well, one measure is implementation time. Blueshift says can be operational in as one day (if data is loaded through an existing Web page tag or push-button integration with Segment) or under two weeks if some work is required. Technically, this is plausible: the system has JSON API that can accept pretty much anything and will put it into MongoDB and/or Postgres with minimal data modeling.
Another measure of simplicity is the campaign building interface. Blueshift lets users specify a sequence of steps by filling out forms to define the segment, channel, and content template for each step and time between steps. This is nowhere near as pretty or flexible as graphical flow charts, but does qualify as simple.
Segments are also built using forms to define one or more filters. Again, nothing fancy but it gets the job done. What’s more important is that the segments can use a wide range of data including online behaviors, attributes from CRM and other systems, predictive model scores, and product information from catalogs. This is what gives the system its power. Content templates do incorporate some visualization, as well as tokens for personalization and machine learning-based product recommendations. Split testing, ecommerce integration, and predictive models for activation, churn and repeat purchase are available in advanced versions of the system. Reports show model performance and attributes, segment counts, and campaign results using several basic attribution methods.
So, apart from some missing bells and whistles, what doesn’t Blueshift do? The main limit is that it works only with known individuals (i.e., those reachable through an email or SMS address, app registration, or similar identifier) and primarily in outbound channels. This means that Web display ads, site personalization, and anonymous visitor targeting aren’t part of the mix, aside from retargeting. And, while data and models are updated continuously, the system isn’t designed to manage real-time interactions.
Blueshift was launched earlier this year. It has more than ten clients, who are mostly multi-channel marketers with a majority of revenue from mobile payments.
In sum, Blueshift isn’t the fanciest marketing system available but it provides a solid mix of highly usable features at a reasonable price. B2C marketers will find it worth a look.
Friday, April 24, 2015
Bombora Feeds B2B Data to Everyone

A couple of emails later and I was on the phone with Erik Matlick, Madison Logic founder and Bombora CEO. We went through a bit of the back story: Madison Logic was founded as a B2B media company six years ago. It built a network of B2B publishers to sell ads and gather data about their site visitors. Both businesses grew nicely, but the company found that selling media conflicted with finding partners to gather data. So last November it spun off the data piece as Madison Logic Data, keeping Madison Logic as the media business. The change from Madison Logic Data to Bombora was announced on April 13.
To which you probably say, who cares? Fair enough. What really matters is what Bombora does today and, more pointedly, what it can do for you. Turns out, that’s quite a bit.
Bombora’s core business is assembling data about B2B companies and individuals. It does this through a network of publishers who put a Bombora pixel on their Web pages. This lets Bombora track activities including article and video viewing, white paper downloads, Webinar attendance, on-site search, and participation in online communities. The company tags its publishers' content with a 2,300-topic taxonomy, allowing it to associate visitors with intent based on the topics they consume. It identifies visitors based on IP address, domain, and registration forms on the publisher sites. It also attaches demographic information based on information they provide on the registration forms and the publishers have in their own profiles. The volumes are huge: 4 billion transactions per month, more than 250 million business decision makers, and 85 million email addresses collected in a year.
All that information has many uses: [feel free to insert your favorite cliché about how data being important]. Like meat packers who use every part of the pig but the squeal, Bombora is determined the squeeze the most value possible from the data it assembles. This means selling it intent and demographic audience segments for display advertising, marketing automation and email segmentation, Web audience analytics, data enhancement, content personalization, media purchasing, and predictive modeling. Different users get different data: sometimes cookies, device IDs or email addresses, and sometimes by company, individual, or segment. Publishers who contribute data are treated as part of a co-op and get access to all 2,300 intent topics. Others only can select from around 60 summary categories.
If you’re a B2B marketer, you’re probably drooling at the thought of all that data. So why haven’t you heard of Madison Logic and Bombora before? Well, like those thrifty meat packers, Bombora sells only at wholesale. In each channel, partners embed the Bombora data within their own products. Sometimes it's baked into the price and sometimes you pay extra. It’s a “Bombora inside” strategy and makes perfect sense: everything’s better with data.
At the risk of beating a dead pig, I'll also note out that Bombora illustrates a point I've made before: that public sources of data will increasingly supplement and to some degree may even replace privately gathered data. This is a key part of the "madtech" vision that says the data layer of your customer management infrastructure will increasingly reside outside of your company's control. The risk to companies who use this data is that their competitors can access it just as easily, so there's still a need to build proprietary data sources in addition to adding value in other areas such as better analytics or customer experience.
Enough of that. I'm hungry.
_________________________________________________________________
*Something to do with surfing in Australia. There's a sea of data metaphor in there somewhere, I think.
Wednesday, April 15, 2015
Marketo Conference: Is Predictive Modeling The Future of Marketing Automation?

As usual for me, I spent much of conference prowling the exhibit hall checking out old and new vendors. Marketo has attracted a respectable array of partners who extend its capabilities. By far the most notable presence was predictive modeling vendors – Leadspace, Mintigo, Lattice Engines, Infer, Fliptop, SalesPredict, 6Sense, Everstring plus maybe some others I’m forgetting. I’ve written about each of these individually in the past, but seeing them in the same place brought home the very crowded nature of this market. It also prompted many interesting discussions with them vendors themselves, who, not surprisingly, are an especially analytical and thoughtful group.
Many of those conversations started with the large number of vendors now in the space and how many would ultimately survive. I actually found this concern a bit overwrought – there are other segments, most obviously B2B marketing automation itself, that support many dozens of similar vendors. By that standard, predictive analytics is still far from overcrowded. At the risk of some unfair (and unjustifiably condescending) stereotyping, I’ll propose that part of their concern comes from a sort of Spock-like rationality that says only a few different products are really needed in any given segment. That may indeed be logically correct, but real markets often support more players than anyone needs. I see nothing inherent in the predictive marketing industry that will limit it to a few survivors.
In fact, almost immediately after wondering whether there were too many choices, many vendors observed that they were already sorting themselves into specialists serving different customer types or applications. Some products sell mostly to smaller companies, some to companies with many different products, some to customers who want new prospect names, some who want to incorporate external behaviors, and so on. Here, the vendors’ perception is more nuanced than my own; they see differences that I hadn’t noticed. Despite these distinctions, I still expect that most vendors will broaden rather than narrow their scope over time. But maybe that’s my own inner Spock looking for more simplicity than really exists.
One factor simplifying buyers' selection decision was that nearly all clients test multiple systems before making a purchase. This contrasts sharply with marketing automation, where many companies still buy the first system they consider and few conduct an extensive pre-purchase trial. The main reason for this anomaly is that modeling systems are highly testable: buyers give each competitor a set of data, let them build a model, and can easily see whose scores do a better job of identifying right people. It also probably helps that people buying predictive systems are generally more sophisticated marketers. There's some danger to relying extensively on test results, since they obscure other factors such as time to build a model and how well models retain their performance over time. I was also a bit puzzled that nearly every vendor reported winning nearly every test. I don't think that's mathematically possible.
Probably the most interesting set of discussions revolved around the long-term relation of predictive functions to the rest of the customer management infrastructure. This was sometimes framed as whether predictive modeling will be a "feature" embedded in other systems or a "product" sold on its own. My intuition is it's a feature: marketers simply want to select on model scores the same way they’d select any other customer attribute, so scoring should be baked into whatever marketing system they’re using. But the counter argument starts with the empirical observation that marketing automation vendors haven’t done this, and speculates that maybe there’s a sound reason: not just that they don’t know how or it’s too hard, but that modeling systems need data that is stored outside of marketing automation or should connect with multiple execution systems that marketing automation does not. The data argument makes some sense to me, although I think marketing automation itself should also connect with those external sources. I don’t buy the execution system argument. Marketing automation should select customer treatments for all execution systems; scores should be an input to the marketing automation selections.
But there’s a deeper version of this question that asks about the role of predictive analytics within the customer management process itself. Marketo CEO Phil Fernandez touched on this indirectly during his keynote, when he observed that literally mapping the customer journey as an elaborate flow chart is inherently unrealistic, because customers follow many more paths than any manageable chart could contain. He also came back to it with the image of a “self-driving” marketing automation system that, like a self-driving car, would let the user specify a goal and then handle all the details independently. Both examples suggest replacing marketer-created rules to guide customer treatments with predictive systems that select the best action in each situation. As several of the predictive vendors pointed out to me (with what sounded like the voice of painful experience), this requires marketers to give up more control than they may find comfortable – either because machines really can’t do this or because it would put marketers out of a job if the machines could. Personally, I'll bet on the machines in this contest, although with many caveats about how long it will take before humans are fully or even largely replaced.
However, and here’s the key point that came up in the most interesting discussions: predictive models can’t do this alone. At the most abstract, marketing involves picking the best customer treatment in each situation. But models can only pick from the set of treatments that are available. In other words, someone (or some thing) has to create those treatments and, prior to that, decide what treatments to create. In current marketing practice, those decisions are made with a content map that plots available content against customer life stages and personas. This makes sure that appropriate content is available for each situation. Proper value measurement – which means estimating the incremental impact on lifetime value of each marketing message – also relies on persons and life stages as a framework. So any machine-based approach to customer management has to generate personas, life stages, and content to be complete.*
I see no inherent reason that machines couldn’t ultimately do the persona and life stage definition. None of vendors do it today, although several appear to have given it some thought. Automated content creation is already available to a surprising degree and will only get better. But, to get back to my point: the technologies to do these things are very different from predictive modeling. So if new technology is to replace marketing automation as the controller of customer treatments, that technology will include much more than predictive modeling by itself.
_________________________________________________________________________
* Yes, it has occurred to me that a fully machine driven system might not need personas and lifestages, which are aggregations needed because humans can't deal with each person separately. But marketers won't adopt that approach until (a) machines can also create content without the persona / lifestage framework and (b) humans are willing to trust the black box so completely they don't need personas and lifestages to help understand what the machines are up to. On the other hand, you could argue that content recommendation engines like BrightInfo (also at the Marketo show) already work without personas and lifestages...although I think they usually focus on a near-term action like conversion rather than long-term impact like incremental lifetime value.
Friday, October 24, 2014
SalesPredict Offers Highly Automated, Highly Flexible Predictive Modeling
A couple of weeks ago, I wrote that “predictive everywhere” is one of major trends in data-driven marketing. I meant both that predictive models guide decisions at every stage in many marketing programs, and that models are used throughout the organization by marketing, sales, and service.
I might have added a third meaning: that systems to do predictive modeling are everywhere as well. SalesPredict is a perfect example: a small vendor with a powerful system that just launched earlier this year. Back in, say, 2008, a product like this would be big news. Today, I simply add them to my list and try to understand what makes them different.

In this case, the main technical differentiator is extreme automation: SalesPredict imports customer data, builds models, scores current records, and deploys the results with virtually no human intervention. This is possible primarily because the painstaking work of preparing data for analysis – which is where model builders spend most of their time – is avoided by connecting to a few standard sources, currently Salesforce.com and Marketo with HubSpot soon to follow. Because it knows what to expect, the system can easily load customer data and sales results from those systems. It then enhances the data with business and demographic information from public Web pages, social profiles, and third party sources including Zoominfo, InsideView, and Orb Intelligence. Finally, it produces models that rank customers based on how closely they resemble members of any user-specified list, such as customers with deals that closed or who failed to renew. Results appear as lists in a CRM interface or as scores on a marketing databaset. The whole process takes just a few hours from making the Salesforce.com connection to seeing scored records, with most of the time spent downloading CRM data and scanning the Web for other information. Once SalesPredict is installed, models are continuously updated based on new CRM information and on feedback provided by users as they review the scored records. This enables the system to automatically adjust as buyer behaviors and conditions change.
User interface is a second differentiator. CRM users see a ranked list of customer records with a system-assigned persona derived using advanced natural language processing, suggested actions such as which products to offer, and the key data values that influenced the ranking. Users can drill further into each record to see more customer and company information including previous interactions, products owned, and won or lost deals. The company information is assembled from internal and external sources using SalesPredict’s own matching methods, so results are not at the mercy of data quality within the CRM. As previously noted, users can adjust a ranking if they feel the model is wrong; this is fed back to the system to adjust future predictions. Another screen shows which data values are most powerful in predicting success. This helps users understand the model and suggests criteria for targeting increased marketing investment. Although there’s no great technical wizardry required to provide these interfaces (except perhaps the name and account matching), they do make results more easily understood than many other predictive modeling products.
The final differentiator is flexibility. The system can model against any user-defined list, meaning that SalesPredict can score new leads, identify churn risk, or find the most likely buyers for new products. Recommendations also draw on a common technology, whether the system is suggesting which products a customer is most likely to buy, which content they are most likely to download, or which offers they are most likely to accept. That said, SalesPredict’s primarily integration with Salesforce.com, user interface, and company name itself suggest the vendor’s main focus is on helping sales users spend their time on the most productive lead. This is somewhat different from predictive modeling vendors who have focused primarily on helping marketers with lead scoring.
Is SalesPredict right for you? Well, the automation and flexibility are highly attractive, but the dependence on CRM data may limit its value if you want to incorporate other sources. Pricing was originally based on the number of leads but is currently being revised, with no new details available. However, it’s likely that the company will remain small-business-friendly in its approach. SalesPredict currently has about 15 clients, mostly in the technology industry but also with some in financial services and healthcare.
I might have added a third meaning: that systems to do predictive modeling are everywhere as well. SalesPredict is a perfect example: a small vendor with a powerful system that just launched earlier this year. Back in, say, 2008, a product like this would be big news. Today, I simply add them to my list and try to understand what makes them different.
In this case, the main technical differentiator is extreme automation: SalesPredict imports customer data, builds models, scores current records, and deploys the results with virtually no human intervention. This is possible primarily because the painstaking work of preparing data for analysis – which is where model builders spend most of their time – is avoided by connecting to a few standard sources, currently Salesforce.com and Marketo with HubSpot soon to follow. Because it knows what to expect, the system can easily load customer data and sales results from those systems. It then enhances the data with business and demographic information from public Web pages, social profiles, and third party sources including Zoominfo, InsideView, and Orb Intelligence. Finally, it produces models that rank customers based on how closely they resemble members of any user-specified list, such as customers with deals that closed or who failed to renew. Results appear as lists in a CRM interface or as scores on a marketing databaset. The whole process takes just a few hours from making the Salesforce.com connection to seeing scored records, with most of the time spent downloading CRM data and scanning the Web for other information. Once SalesPredict is installed, models are continuously updated based on new CRM information and on feedback provided by users as they review the scored records. This enables the system to automatically adjust as buyer behaviors and conditions change.
User interface is a second differentiator. CRM users see a ranked list of customer records with a system-assigned persona derived using advanced natural language processing, suggested actions such as which products to offer, and the key data values that influenced the ranking. Users can drill further into each record to see more customer and company information including previous interactions, products owned, and won or lost deals. The company information is assembled from internal and external sources using SalesPredict’s own matching methods, so results are not at the mercy of data quality within the CRM. As previously noted, users can adjust a ranking if they feel the model is wrong; this is fed back to the system to adjust future predictions. Another screen shows which data values are most powerful in predicting success. This helps users understand the model and suggests criteria for targeting increased marketing investment. Although there’s no great technical wizardry required to provide these interfaces (except perhaps the name and account matching), they do make results more easily understood than many other predictive modeling products.
The final differentiator is flexibility. The system can model against any user-defined list, meaning that SalesPredict can score new leads, identify churn risk, or find the most likely buyers for new products. Recommendations also draw on a common technology, whether the system is suggesting which products a customer is most likely to buy, which content they are most likely to download, or which offers they are most likely to accept. That said, SalesPredict’s primarily integration with Salesforce.com, user interface, and company name itself suggest the vendor’s main focus is on helping sales users spend their time on the most productive lead. This is somewhat different from predictive modeling vendors who have focused primarily on helping marketers with lead scoring.
Is SalesPredict right for you? Well, the automation and flexibility are highly attractive, but the dependence on CRM data may limit its value if you want to incorporate other sources. Pricing was originally based on the number of leads but is currently being revised, with no new details available. However, it’s likely that the company will remain small-business-friendly in its approach. SalesPredict currently has about 15 clients, mostly in the technology industry but also with some in financial services and healthcare.
Subscribe to:
Posts (Atom)


