
By now, you can probably recite along with me as I list the key differentiators for predictive systems. Let’s run through them with Wise.io as the subject.
• inputs. Wise.io connects to any system with an open API, which includes most major software-as-a-service products. Vendor staff does some basic mapping for each client, which usually takes a couple of hours at most. Most of that time is spent working with the client to decide what data to include in the feed. One important feature of Wise.io is that it can handle very large numbers of inputs – hundreds or thousands of elements – so there’s not much pressure to restrict the inputs too carefully. The system can also take non-API feeds such as batch data loads, although this takes more custom work. It can handle pretty much any type of data and includes advanced natural language processing to extract information from text.
• external data. Many predictive modeling systems, especially for B2B lead scoring, supplement the client’s data with company and individual information they gather themselves from sources like social networks, Web sites, job boards, and government files. Wise.io doesn’t do this.
• data management. Wise.io maintains a database of information it has loaded from source systems. It can accept inputs from multiple sources in different formats. Data is stored on Amazon S3 and Postgres, allowing Wise.io to handle very large volumes. But the system doesn’t link records belonging to the same individual or company unless they have already been coded with a common key.
• automation. Wise.io has almost fully automated the data loading, variable selection, model building, and scoring processes. The system has sophisticated features to automatically adjust for missing values, outliers, inconsistencies, and similar real-world problems that usually require human intervention. To build a new model, users simply select the items to predict and the locations to place the results. The system’s machine learning engine automatically uses existing records in the client’s database to create the model and then places the predictions in the specified fields.
• set-up time. New clients usually have their first model within one day, assuming credentials are available to connect with source systems and the vendor and client can quickly agree on what to import. This is about as quick as it gets. While other vendors work even faster, they do this by limiting themselves to prebuilt connectors to standard systems. There’s nothing wrong with that but bear in mind that even those vendors will take longer once you start to add other inputs.
• outputs. Wise.io generates predictions, confidence scores for the predictions, and lists of drivers that show the reasons for the predictions. These are loaded into client systems where they can generate reports (see below) or be integrated with CRM or customer support agent interfaces.
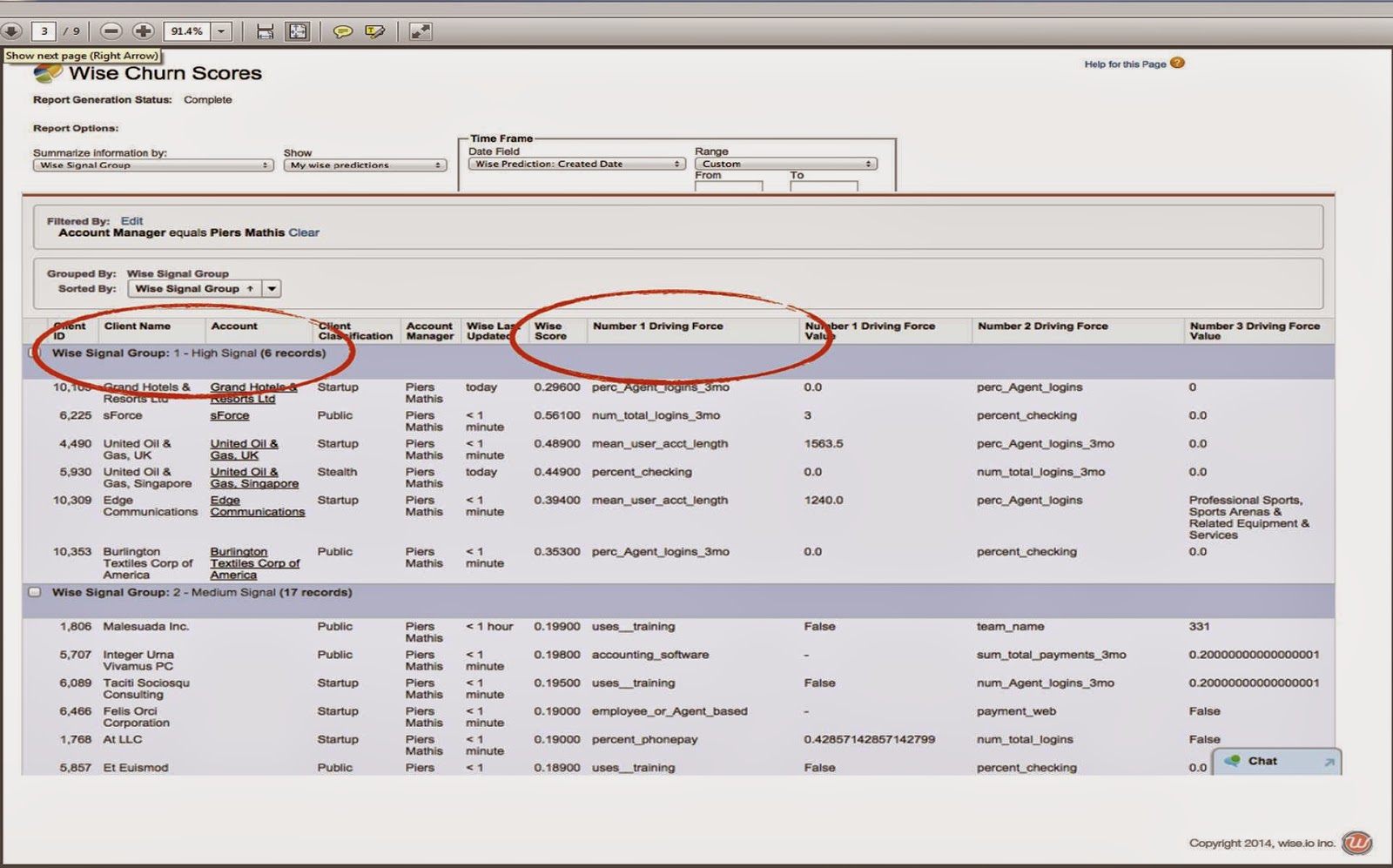
• self-service. After the initial setup, clients can build new models for themselves through a simple interface that basically involves specifying the source data, item to predict, and destination for the results. Adding a new data source would take some help from the vendor but should be pretty quick unless the source lacks a standard API or export tools.
• update frequency. Wise.io will load data in real time as it is updated in client systems, assuming the client system supports this. Scores will reflect the latest data. The system continuously and automatically updates its models to reflect new results.
• applications. Wise.io can be used for pretty much any predictive application, but the company has focused its initial efforts on customer support and retention. This involves tasks such as identifying churn risks and assigning support cases to the proper agent.
• cost. Pricing is based on the number of predictions the system generates, whether those are support tickets, email messages, or customer lists. Enterprise edition installations start in the mid-five figures (i.e., around $50,000) and can go considerably higher. A new self-service edition is limited to specific marketing automation, customer support, and CRM systems and costs somewhat less.
• vendor. The company was launched in 2013 and has some modest venture funding (published figures range from $2.5 million to $3.5 million). It has about a dozen production clients and another two dozen or so in pilot. Client include both consumer and business marketers.




