Summary: LoopFuse has launched a free entry-level version of its marketing automation system. It's one example of how vendors are now competing to attract new users. Only the winners will survive industry consolidation, which may be here sooner than you think.
LoopFuse today promised to “transform” the marketing automation industry by offering a free version of its system. Although LoopFuse and others already provide free trials, this is indeed different: while most free trials expire after 30 days and often have limited functionality, LoopFuse’s FreeView can be used for as long as you like and provides pretty much the same features as the paid version of the system. The critical constraint is that volume is limited to 2,500 prospect names, 5,000 emails and 100,000 page views per month. In practice, this means that only very small companies will actually be able to use the free system as their primary long-term marketing system.
LoopFuse knows that, of course. When they briefed me last week, they said the main purpose of the new system is really to entice trial among companies just starting with marketing automation. They’ll make their money when users see the value they gain and pay for higher volumes and add-on features.
Personally, I’d argue that the really significant news out of LoopFuse is their newly tiered pricing structure. The entry point of $350 per month (for up to 10,000 prospects with unlimited emails and page views) is much lower than the $1,000 to $2,000 starting price of most full-function marketing automation systems. Prices at higher volumes are also much lower than competitors. This will put substantial pricing pressure on vendors who, in many cases, are already struggling to reach sustainable margins.
Here’s where the free system comes back into play. To make a free product viable, LoopFuse needed to engineer as much cost as possible out of the entire client life cycle. This means it had to be possible for clients to purchase and configure the system, learn how to use it and resolve support issues with next to no involvement by LoopFuse staff. Once this was accomplished, LoopFuse was in a position to charge lower fees to its paying clients as well. Other vendors – notably Pardot – have followed a similar cost-removal strategy. But LoopFuse may have been more focused than anyone else.
This doesn’t mean that LoopFuse’s success is guaranteed. Other vendors have similar price points for the small business market (see my list of demand generation vendors) although I suspect their internal costs are higher.
More important, price is just one factor in picking a system. Features, ease of use, and support from the vendor and business partners are usually (and rightly) the main considerations. The free product should increase the number of companies that try LoopFuse first, which will gain it paying customers down the road. But I think that most buyers will recognize that they are likely to stay with their first system and conduct a careful evaluation before they start.
For evidence that a free entry-level product does not automatically drive out higher priced systems, consider the hosted CRM market. Salesforce.com easily dominates despite the presence of surprisingly capable free products like ZohoCRM and FreeCRM .
Whatever the result for LoopFuse, the new offering is part of a larger pattern within the industry. Marketing automation (more precisely, B2B marketing automation) has now passed beyond the pioneer stage where fundamentally different approaches compete for acceptance. At this point, we all pretty much know what a marketing automation system does and, truth be told, the major systems are functionally quite similar.
Competition now shifts from building a technically better system to surviving the inevitable industry consolidation. This requires finding ways to attract masses of new customers as they enter the market.
LoopFuse’s price-driven approach is one such strategy. But many vendors have recently taken others:
- Eloqua, Silverpop, True Influence and at least one other vendor I can’t name are planning new interfaces that they believe will substantially improve ease of use, which they see as the critical barrier blocking many potential buyers. I’m skeptical that truly radical improvements are possible but am certainly eager to see what they come up with.
- LeadLife has embedded best practice hints throughout its system, another way to support adoption by users who lack marketing automation knowledge.
- Infusionsoft has repositioned itself as “email 2.0” rather than marketing automation. They believe this makes it easier for their target customers (under 25 employees) to see them as the next logical step beyond standard email.
- Genius.com added a new Demand Generation edition that falls between its basic Email Marketing and full-blown Marketing Automation products. This is another way of easing the transition from basic email marketing.
- LeadForce1 launched a solution that uses advanced text analysis to measure user intent, and thus provide much better guidance to salespeople than conventional behavioral analysis. Although their approach is based on superior technology, it's still a way to attract customers by offering radically greater value than competitors.
- Marketo now calls itself a “the revenue cycle management company”, giving equal public weight to lead management, sales insight and analytics. They still haven’t briefed me on this or their features to support large enterprises, but they seem to be seeking larger, more sophisticated clients who will presumably provide higher profit margins. Given how many other vendors are targeting small businesses, this certainly makes sense. But Marketo will also find itself competing with established marketing automation vendors like Aprimo, Neolane and Unica. who are entering this market from a different direction. It will also be competing with Eloqua, Silverpop and, perhaps most dangerously, the Market2Lead technology recently purchased by Oracle.
The Market2Lead-Oracle deal raises the other major question facing marketing automation vendors: what role CRM vendors will play? In addition to Oracle, CDC Software (owner of Pivotal CRM and MarketFirst) recently invested in Marketbright.
Of course, the really big question is whether Salesforce.com will make a similar move. There have been off-and-on rumors along those lines for months, followed by stout (if not necessarily credible) denial from Salesforce.com that it has any interest in that direction. I’ve tended to take them at their word, but Oracle and Salesforce.com are blood rivals, so Oracle’s move could easily prompt a Salesforce.com reaction.
Oddly enough, no seems to consider whether Microsoft will enter the game. That's surely a possibility, and would move towards a certainty if its two big on-demand CRM rivals both added marketing automation products. We might even see Google and Intuit participate: both already sell to small business marketers.
My fundamental conclusion is that the B2B marketing automation industry is about to enter the long-predicted stage of vendor consolidation, and that this will move quite quickly. The survivors will serve particular market segments: primarily small vs. large businesses, plus possibly some vertical industry specialization. The window for new entrants is rapidly closing, so any new player will need a major differentiator that creates a clear advantage and distinct identity.
Wednesday, June 30, 2010
Monday, June 28, 2010
Saffron Technology Organizes Data into Memories
Summary: Saffron Technology provides an analytical database that explores relationships among entities and their attributes. It can explore networks, find similarities and guide decisions. Saffron is considerably more flexible than standard semantic engines.
As I was preparing my June 3 review of link analysis vendor Centrifuge Systems, Centrifuge introduced me to their business partners at Saffron Technology. This is an interesting product in its own right.
Saffron describes itself as an “associative memory base product,” a phrase that definitely takes some explaining. In simplest terms, Saffron organizes information into sets of three or four related items.
More specifically, it stores pairs of items in the context of an entity. For example, “Jack-climb-hill”, “Jack-plant-beanstalk”, “Jack-jump-candlestick” and “Jack-build-house” are all part of what Saffron calls Jack’s “memory”.
Related sets can be grouped into "matrices" that share another item. Thus, one matrix could contain “Jack-Jill-up-hill”, “Jack-Jill-fetch-water”, “Jack-Jill-fall-down” and “Jack-Jill-break-crown”, while “Jack-beanstalk-plant-seed”, “Jack-beanstalk-climb-up”, “Jack-beanstalk-steal-harp” and “Jack-beanstalk-kill-giant” form a separate matrix.
Saffron physically prejoins the data in Jack’s memory so it can be accessed easily and shared elements can be stored only once. Jill’s memory is stored separately from Jack’s even though some sets contain the same data. Jill’s memory may also contain sets without Jack (but let’s not tell him). Depending on how the system is configured, the hill could have its own memory as well.
Saffon’s approach lets it handle the subject-verb-object triples used in semantic analysis. But unlike standard semantic triplestores, Saffron is not limited to this structure. Sets could contain all nouns (Jack-Jill-hill), which can be useful even if the precise relationship among the items isn’t known. Or one of the items could be a time dimension. The system also counts of how often each item pair occurs in the source data, supporting statistical as well as semantic analysis.
These features make Saffron substantially more flexible than a semantic system. They also let it work with many more data sources, since reliable subject-verb-object relationships are often unavailable.
This may sound pretty dry, but Saffron's actual applications have been cloak-and-dagger stuff like looking for terrorists and finding roadside bombs. Remember that I was introduced to Saffron by Centrifuge, whose link analysis system is used primarily for law enforcement and security investigations. Saffron’s approach works particularly well with the Centrifuge front-end.
The fundamental advantage of Saffron is that associations among different items are directly accessible for analysis. This lets the system support different types of queries including:
- connections (identifying relationships among items)
- networks (showing how entities connect with each other)
- analogies (finding entities with similar connections)
- classifications (placing similar entities into groups)
- trends (reporting how connections change over time)
- episodes (finding patterns that repeat over time)
Real-world applications extend beyond link analysis to classifications and decisions. For example, the system can select medical treatments for a particular patient or assign suspended loans to different collection processes. These are complex processes. The system must identify entities with similar characteristics, identify the treatments and outcomes for those entities and estimate the likely outcomes of applying different treatments to the current entity.
Saffron's advantage with such applications is that the characteristics, treatments and outcomes are all just items in the data store. There's no need to load them differently or build a causal model of how they interact. In other words, the system needs no inherent assumptions about how the world works. This lets it effortlessly incorporate new data, uncover hidden relationships and react to new situations.
Well, “effortlessly” is a bit of an exaggeration. Saffron does some pretty complicated calculations to decide which entities are most similar and which treatments have the highest expected value (i.e., outcome value x outcome probability). Users have to review results and make judgments to tune the system. But this is still much less work than conventional statistical modeling or rule-based systems.
Saffron’s technology lets users define the types of data to will store, load data into the system, and execute API calls for the different types of analysis (connections, networks, analogies, etc.) Saffron generally relies on external systems to identify entities within source data, classify them into the specified categories, and report their associations to Saffron. Saffron can load structured data as well.
Saffron runs on a 64 bit “soft appliance” that distributes its data over clusters of server drives. The company claims world-record performance at ingesting, storing and accessing triplestore data, as well as compression to about 20 bytes per triple compared with 50 to 150 bytes per triple in other triplestore systems.
But let’s not get too carried away: Saffron works with large but not gigantic databases. Customer systems have been in the one-terabyte range.
Pricing for Saffron is starts at $125,000 per server, where a standard server is an eight core machine with 16 gigabytes of RAM per core. A trial version of the system is also available on the Amazon EC2 cloud as SaffronSierra.
As I was preparing my June 3 review of link analysis vendor Centrifuge Systems, Centrifuge introduced me to their business partners at Saffron Technology. This is an interesting product in its own right.
Saffron describes itself as an “associative memory base product,” a phrase that definitely takes some explaining. In simplest terms, Saffron organizes information into sets of three or four related items.
More specifically, it stores pairs of items in the context of an entity. For example, “Jack-climb-hill”, “Jack-plant-beanstalk”, “Jack-jump-candlestick” and “Jack-build-house” are all part of what Saffron calls Jack’s “memory”.
Related sets can be grouped into "matrices" that share another item. Thus, one matrix could contain “Jack-Jill-up-hill”, “Jack-Jill-fetch-water”, “Jack-Jill-fall-down” and “Jack-Jill-break-crown”, while “Jack-beanstalk-plant-seed”, “Jack-beanstalk-climb-up”, “Jack-beanstalk-steal-harp” and “Jack-beanstalk-kill-giant” form a separate matrix.
Saffron physically prejoins the data in Jack’s memory so it can be accessed easily and shared elements can be stored only once. Jill’s memory is stored separately from Jack’s even though some sets contain the same data. Jill’s memory may also contain sets without Jack (but let’s not tell him). Depending on how the system is configured, the hill could have its own memory as well.
Saffon’s approach lets it handle the subject-verb-object triples used in semantic analysis. But unlike standard semantic triplestores, Saffron is not limited to this structure. Sets could contain all nouns (Jack-Jill-hill), which can be useful even if the precise relationship among the items isn’t known. Or one of the items could be a time dimension. The system also counts of how often each item pair occurs in the source data, supporting statistical as well as semantic analysis.
These features make Saffron substantially more flexible than a semantic system. They also let it work with many more data sources, since reliable subject-verb-object relationships are often unavailable.
This may sound pretty dry, but Saffron's actual applications have been cloak-and-dagger stuff like looking for terrorists and finding roadside bombs. Remember that I was introduced to Saffron by Centrifuge, whose link analysis system is used primarily for law enforcement and security investigations. Saffron’s approach works particularly well with the Centrifuge front-end.
The fundamental advantage of Saffron is that associations among different items are directly accessible for analysis. This lets the system support different types of queries including:
- connections (identifying relationships among items)
- networks (showing how entities connect with each other)
- analogies (finding entities with similar connections)
- classifications (placing similar entities into groups)
- trends (reporting how connections change over time)
- episodes (finding patterns that repeat over time)
Real-world applications extend beyond link analysis to classifications and decisions. For example, the system can select medical treatments for a particular patient or assign suspended loans to different collection processes. These are complex processes. The system must identify entities with similar characteristics, identify the treatments and outcomes for those entities and estimate the likely outcomes of applying different treatments to the current entity.
Saffron's advantage with such applications is that the characteristics, treatments and outcomes are all just items in the data store. There's no need to load them differently or build a causal model of how they interact. In other words, the system needs no inherent assumptions about how the world works. This lets it effortlessly incorporate new data, uncover hidden relationships and react to new situations.
Well, “effortlessly” is a bit of an exaggeration. Saffron does some pretty complicated calculations to decide which entities are most similar and which treatments have the highest expected value (i.e., outcome value x outcome probability). Users have to review results and make judgments to tune the system. But this is still much less work than conventional statistical modeling or rule-based systems.
Saffron’s technology lets users define the types of data to will store, load data into the system, and execute API calls for the different types of analysis (connections, networks, analogies, etc.) Saffron generally relies on external systems to identify entities within source data, classify them into the specified categories, and report their associations to Saffron. Saffron can load structured data as well.
Saffron runs on a 64 bit “soft appliance” that distributes its data over clusters of server drives. The company claims world-record performance at ingesting, storing and accessing triplestore data, as well as compression to about 20 bytes per triple compared with 50 to 150 bytes per triple in other triplestore systems.
But let’s not get too carried away: Saffron works with large but not gigantic databases. Customer systems have been in the one-terabyte range.
Pricing for Saffron is starts at $125,000 per server, where a standard server is an eight core machine with 16 gigabytes of RAM per core. A trial version of the system is also available on the Amazon EC2 cloud as SaffronSierra.
Tuesday, June 22, 2010
Privacy: Does Anybody Care?
To paraphrase HL Mencken, no one ever went broke underestimating the American public's commitment to privacy. "Quit Facebook Day" reportedly generated 31,000 account closings, compared with the roughly 500,000 new accounts that Facebook adds each day.
This lack of interest in privacy is a tremendous pity, because privacy violations can cause many types of real harm:
- identity theft
- physical violations including stalking and burglary when people are known to be out
- unjustified commercial treatment (e.g. denial of credit or employment) based on irrelevant or incorrect information
- unjustified government activity (e.g., placement on a No Fly list) based on irrelevant or incorrect information
Ironically, such problems seem to generate less public concern than techniques such as "behavioral targeting", even though the consequence of that is...um...receiving a relevant advertisement. I fully understand the real issue is people feel creepy to know that someone is sort-of watching them. But it's probably a good thing to remind them because the watching will continue whether behavioral targeting is regulated or not.
As the Facebook example shows, most people really don't care enough about privacy to protect it at the cost of other benefits, even minor ones like participating in Facebook. Similarly, many Americans seem downright eager to sacrifice their privacy from government surveillance in the name of national security.
The pity is that it's not an either/or choice. In many cases, technology can be designed to preserve privacy and still give the desired benefits. As a good example of what privacy-consciousness looks like when someone really cares, consider how the gun buyers are protected: gun dealers must check buyers' names against a database of felons, but the buyers' names are erased after a few days. (Of course, loopholes apply to "gun shows" but that's another discussion.) Another example -- never implemented so far as I know -- is that instead of reading drivers license information to prove patrons are old enough to drink, bars could have devices that simply scan the license and flash a green or red light depending on whether the person is old enough.
The point in both cases is that systems can be designed to access and retain the minimum amount of information necessary to fulfill their function. Many behavioral targeting systems already work this way -- capturing relevant data but not the actual identity of an individual. These principles could be applied more broadly and more systematically, but only if the people designing and regulating these systems made them a priority.
In practice it seems that other, less rational approaches are being adopted because they are more popular. To quote Mencken again, “For every problem there is a solution which is simple, clean and wrong.”
Without being excessively cynical, I think it's relevant to point out that privacy doesn't have much of a lobby, at least compared with, say, the National Rifle Association. Businesses want to collect data for marketing purposes. Consumer-friendly government officials are the natural opponents of this collection, but are constrained because many government agencies want the data for their own social and security purposes. The only organized opposition comes from a small set of privacy activists who themselves vary considerably in their priorities and capabilities. This means that, as a marketer, I don't spend much energy worrying about seriously restrictive privacy regulations -- even though I'd actually like to see some intelligent restrictions on data gathering by both business and government.
This lack of interest in privacy is a tremendous pity, because privacy violations can cause many types of real harm:
- identity theft
- physical violations including stalking and burglary when people are known to be out
- unjustified commercial treatment (e.g. denial of credit or employment) based on irrelevant or incorrect information
- unjustified government activity (e.g., placement on a No Fly list) based on irrelevant or incorrect information
Ironically, such problems seem to generate less public concern than techniques such as "behavioral targeting", even though the consequence of that is...um...receiving a relevant advertisement. I fully understand the real issue is people feel creepy to know that someone is sort-of watching them. But it's probably a good thing to remind them because the watching will continue whether behavioral targeting is regulated or not.
As the Facebook example shows, most people really don't care enough about privacy to protect it at the cost of other benefits, even minor ones like participating in Facebook. Similarly, many Americans seem downright eager to sacrifice their privacy from government surveillance in the name of national security.
The pity is that it's not an either/or choice. In many cases, technology can be designed to preserve privacy and still give the desired benefits. As a good example of what privacy-consciousness looks like when someone really cares, consider how the gun buyers are protected: gun dealers must check buyers' names against a database of felons, but the buyers' names are erased after a few days. (Of course, loopholes apply to "gun shows" but that's another discussion.) Another example -- never implemented so far as I know -- is that instead of reading drivers license information to prove patrons are old enough to drink, bars could have devices that simply scan the license and flash a green or red light depending on whether the person is old enough.
The point in both cases is that systems can be designed to access and retain the minimum amount of information necessary to fulfill their function. Many behavioral targeting systems already work this way -- capturing relevant data but not the actual identity of an individual. These principles could be applied more broadly and more systematically, but only if the people designing and regulating these systems made them a priority.
In practice it seems that other, less rational approaches are being adopted because they are more popular. To quote Mencken again, “For every problem there is a solution which is simple, clean and wrong.”
Without being excessively cynical, I think it's relevant to point out that privacy doesn't have much of a lobby, at least compared with, say, the National Rifle Association. Businesses want to collect data for marketing purposes. Consumer-friendly government officials are the natural opponents of this collection, but are constrained because many government agencies want the data for their own social and security purposes. The only organized opposition comes from a small set of privacy activists who themselves vary considerably in their priorities and capabilities. This means that, as a marketer, I don't spend much energy worrying about seriously restrictive privacy regulations -- even though I'd actually like to see some intelligent restrictions on data gathering by both business and government.
Wednesday, June 16, 2010
Checklists for Selecting a Marketing Automation System
Summary: here are some checklists to help select a marketing automation system. For more details, attend my Focus Webinar on June 29.
On June 29, I'll be giving a Webinar on “Matching a Marketing Automation System to Your Needs”, part of a day-long set of all-star lead management presentations organized by the Focus online business community. (Click here to register; it’s free.) Here's a bit of a preview.
My message boils down to two words: "use case". That is, prepare detailed use cases for the tasks you need and then have each potential vendor demonstrate how their system would execute them. The point is to focus on your actual requirements and not a generic list of capabilities or vendor rankings.
Another way to put it is: eat your vegetables. Don’t try to avoid the hard work of figuring out what you need the system to do. You’ll have to do that anyway, during implementation. But if you wait until then, you may find out too late that you selected the wrong system.
Even buyers who assess their needs may need some help figuring out what features those needs imply. Here are five tables extracted from the Webinar with some useful details.
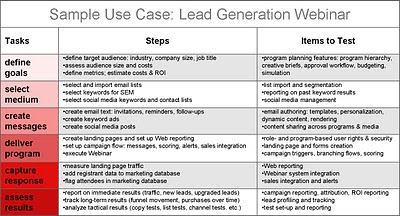
The first table shows a sample use case for a Webinar program. (Click on the image to enlarge it.) It illustrates the need for the use case to be specific, both in terms of describing a specific marketing program and of describing the steps to execute the program. Most marketers could put together the first two columns, Tasks and Steps, from their own knowledge. The remaining column, Items to Test, lists system features that may be unfamiliar to marketers who have not previously worked with a marketing automation system. You may need some help (say, from consultants like Raab Associates Inc.) with adding this column to your own use cases.
The second table looks at functions for different types of marketing programs. The premise is that you need different marketing programs for each step in the customer life cycle, starting with awareness generation and ending with retention. Ideally you’ll have programs in each category, but in practice some categories are more important than others. To help focus your selection process on those high-priority categories, the table describes when each category is likely to be important. It then lists the key system function for each category and the specific features related to those functions.

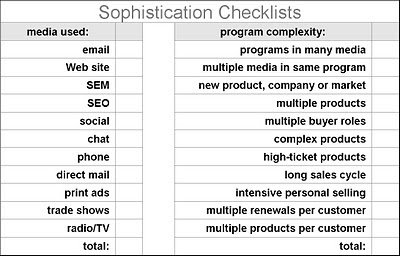
The third table helps to assess the complexity of your needs. The first column describes the media you'll use and the second lists business characteristics contributing to program complexity. Required media can be directly compared with the media supported by potential vendors. Program complexity is a little trickier, but I’d consider your needs complex if more than three or four of the factors are present.
The fourth table is aimed at companies with complex programs. It lists specific requirements you may have and the features needed to meet them. Marketers who don’t need these features may be able to save some time and money by purchasing a system that doesn’t have them built in. On the other hand, some (but not all!) systems do a good job of hiding their advanced features when they’re not being used. So don't automatically rule out an advanced system without looking at it more closely. And bear in mind that you may need the more advanced features in the future.

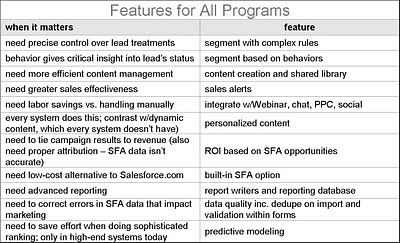
The fifth table applies to all companies regardless of complexity. It lists features that are present in nearly all systems, but vary widely in their details. For each one, you’ll have to think carefully about your specific needs and see how well each vendor can handle them.
These tables don't list all the features you might need in a marketing automation system. Nor do they address other important considerations such as ease of use, support, partners and stability. I'll talk about all those in the Webinar, so be sure to tune in.
On June 29, I'll be giving a Webinar on “Matching a Marketing Automation System to Your Needs”, part of a day-long set of all-star lead management presentations organized by the Focus online business community. (Click here to register; it’s free.) Here's a bit of a preview.
My message boils down to two words: "use case". That is, prepare detailed use cases for the tasks you need and then have each potential vendor demonstrate how their system would execute them. The point is to focus on your actual requirements and not a generic list of capabilities or vendor rankings.
Another way to put it is: eat your vegetables. Don’t try to avoid the hard work of figuring out what you need the system to do. You’ll have to do that anyway, during implementation. But if you wait until then, you may find out too late that you selected the wrong system.
Even buyers who assess their needs may need some help figuring out what features those needs imply. Here are five tables extracted from the Webinar with some useful details.
The first table shows a sample use case for a Webinar program. (Click on the image to enlarge it.) It illustrates the need for the use case to be specific, both in terms of describing a specific marketing program and of describing the steps to execute the program. Most marketers could put together the first two columns, Tasks and Steps, from their own knowledge. The remaining column, Items to Test, lists system features that may be unfamiliar to marketers who have not previously worked with a marketing automation system. You may need some help (say, from consultants like Raab Associates Inc.) with adding this column to your own use cases.

The second table looks at functions for different types of marketing programs. The premise is that you need different marketing programs for each step in the customer life cycle, starting with awareness generation and ending with retention. Ideally you’ll have programs in each category, but in practice some categories are more important than others. To help focus your selection process on those high-priority categories, the table describes when each category is likely to be important. It then lists the key system function for each category and the specific features related to those functions.

The third table helps to assess the complexity of your needs. The first column describes the media you'll use and the second lists business characteristics contributing to program complexity. Required media can be directly compared with the media supported by potential vendors. Program complexity is a little trickier, but I’d consider your needs complex if more than three or four of the factors are present.

The fourth table is aimed at companies with complex programs. It lists specific requirements you may have and the features needed to meet them. Marketers who don’t need these features may be able to save some time and money by purchasing a system that doesn’t have them built in. On the other hand, some (but not all!) systems do a good job of hiding their advanced features when they’re not being used. So don't automatically rule out an advanced system without looking at it more closely. And bear in mind that you may need the more advanced features in the future.

The fifth table applies to all companies regardless of complexity. It lists features that are present in nearly all systems, but vary widely in their details. For each one, you’ll have to think carefully about your specific needs and see how well each vendor can handle them.

These tables don't list all the features you might need in a marketing automation system. Nor do they address other important considerations such as ease of use, support, partners and stability. I'll talk about all those in the Webinar, so be sure to tune in.
Wednesday, June 09, 2010
Using a Purchase Funnel to Measure Marketing Effectiveness: Better than Last-Click Attribution But Far From Perfect
Summary: Many vendors are now proposing to move beyond "last click" attribution to measure the impact of advertising on movement of customers through a sequence of buying stages. This is a definite improvement but not a complete solution.
Marketers have long struggled to measure the impact of individual promotions. Even online marketing, where every click can be captured, and often tracked back to a specific person, doesn’t automatically solve the problem. Merely tracking clicks doesn’t answer the deeper question of the causal relationships among different marketing contacts.
Current shorthand for the issue is “last click attribution” – as in, “why last click attribution isn’t enough”. Of course, vendors only start pointing out a problem when they’re ready to sell you a solution. So it won’t come as a surprise that a new consensus seems to be emerging on how to measure the value of multiple marketing contacts.
The solution boils down to this: classify different contacts as related to the different stages in the buying process and then measure their effectiveness at moving customers from one stage to the next. This is no different from the “sales funnel” that sales managers have long measured, nor from the AIDA model (awareness, interest, desire, action) that structures traditional brand marketing. All that’s new, if anything, is the claim to assign a precise value to individual messages.
Examples of vendors taking this approach include:
- Marketo recently announced new "Revenue Cycle Analytics" marketing measurement features with its customary hoopla. The conceptual foundation of Marketo’s approach is that it tracks the movement of customers through the buying stages. Although this itself isn’t particularly novel, Marketo has added some significant technology in the form of a reporting database that can reconstruct the status of a given customer at various points in the time. Although this is pretty standard among business intelligence systems, few if any of Marketo's competitors offer anything similar.
- Clear Saleing bills itself as an “advertising analytics platform”. Its secret sauce is defining a set of advertising goals (introducer, influencer, or closer) and then specifying which goal each promotion supports. Marketers can then calculate their spending against the different goals and estimate the impact of changes in the allocation. Credit within each goal can be distributed equally among promotions or allocated according to user-defined weights. While such allocation is a major advance for most marketers, it’s still far from perfect because the weights are not based on directly measuring each ad's actual impact.
- Leadforce1 offers a range of typical B2B marketing automation features, but its main distinction is to infer each buyer's position in a four-stage funnel (discovery, evaluation, use, and affinity) based on Web behaviors. The specific approach is to link keywords within Web content to the stages and then track which content each person views. The details are worth their own blog post, but the key point, again, is that the contents are assigned to sales stages and the system tracks each buyer’s progress through those stages. Although the primary focus of LeadForce1 is managing relationships with individuals, the vendor also describes using the data to assess campaign ROI.
Compared with last click attribution, use of sales stages is a major improvement. But it’s far from the ultimate solution. So far as I know, none of the current products does any statistical analysis, such as a regression model, to estimate the true impact of messages at either the individual or campaign level. They either rely on user-specified weights or simply treat all messages within each stage as a group. This lack of detail makes campaign optimization impossible: at best, it allows stage optimization.
Even more fundamentally, stage analysis assumes that each message applies to a single marketing stage. This is surely untrue. As brand marketers constantly remind us, a well-designed message can increase lifetime purchases among all recipients, whether or not they are current customers. It’s equally true that some messages affect certain stages more than others. But to ignore the impact on all stages except one is an oversimplification that can easily lead to false conclusions and poor marketing decisions.
Stage-based attribution has its merits. It gives marketers a rough sense of how spending is balanced across the purchase stages and lets them measure movement and attrition from one stage to the next. Combined with careful testing, it could give insight into the impact of individual marketing programs. But marketers should recognize its limits and keep pressing for solutions that measure the full impact of each program on all their customers.
Marketers have long struggled to measure the impact of individual promotions. Even online marketing, where every click can be captured, and often tracked back to a specific person, doesn’t automatically solve the problem. Merely tracking clicks doesn’t answer the deeper question of the causal relationships among different marketing contacts.
Current shorthand for the issue is “last click attribution” – as in, “why last click attribution isn’t enough”. Of course, vendors only start pointing out a problem when they’re ready to sell you a solution. So it won’t come as a surprise that a new consensus seems to be emerging on how to measure the value of multiple marketing contacts.
The solution boils down to this: classify different contacts as related to the different stages in the buying process and then measure their effectiveness at moving customers from one stage to the next. This is no different from the “sales funnel” that sales managers have long measured, nor from the AIDA model (awareness, interest, desire, action) that structures traditional brand marketing. All that’s new, if anything, is the claim to assign a precise value to individual messages.
Examples of vendors taking this approach include:
- Marketo recently announced new "Revenue Cycle Analytics" marketing measurement features with its customary hoopla. The conceptual foundation of Marketo’s approach is that it tracks the movement of customers through the buying stages. Although this itself isn’t particularly novel, Marketo has added some significant technology in the form of a reporting database that can reconstruct the status of a given customer at various points in the time. Although this is pretty standard among business intelligence systems, few if any of Marketo's competitors offer anything similar.
- Clear Saleing bills itself as an “advertising analytics platform”. Its secret sauce is defining a set of advertising goals (introducer, influencer, or closer) and then specifying which goal each promotion supports. Marketers can then calculate their spending against the different goals and estimate the impact of changes in the allocation. Credit within each goal can be distributed equally among promotions or allocated according to user-defined weights. While such allocation is a major advance for most marketers, it’s still far from perfect because the weights are not based on directly measuring each ad's actual impact.
- Leadforce1 offers a range of typical B2B marketing automation features, but its main distinction is to infer each buyer's position in a four-stage funnel (discovery, evaluation, use, and affinity) based on Web behaviors. The specific approach is to link keywords within Web content to the stages and then track which content each person views. The details are worth their own blog post, but the key point, again, is that the contents are assigned to sales stages and the system tracks each buyer’s progress through those stages. Although the primary focus of LeadForce1 is managing relationships with individuals, the vendor also describes using the data to assess campaign ROI.
Compared with last click attribution, use of sales stages is a major improvement. But it’s far from the ultimate solution. So far as I know, none of the current products does any statistical analysis, such as a regression model, to estimate the true impact of messages at either the individual or campaign level. They either rely on user-specified weights or simply treat all messages within each stage as a group. This lack of detail makes campaign optimization impossible: at best, it allows stage optimization.
Even more fundamentally, stage analysis assumes that each message applies to a single marketing stage. This is surely untrue. As brand marketers constantly remind us, a well-designed message can increase lifetime purchases among all recipients, whether or not they are current customers. It’s equally true that some messages affect certain stages more than others. But to ignore the impact on all stages except one is an oversimplification that can easily lead to false conclusions and poor marketing decisions.
Stage-based attribution has its merits. It gives marketers a rough sense of how spending is balanced across the purchase stages and lets them measure movement and attrition from one stage to the next. Combined with careful testing, it could give insight into the impact of individual marketing programs. But marketers should recognize its limits and keep pressing for solutions that measure the full impact of each program on all their customers.
Thursday, June 03, 2010
Centrifuge Systems Offers Powerful, Flexible Link Analysis
Summary: Centrifuge Systems offers powerful, server-based link analysis and data visualization. It lets non-technical users load their own data, allowing them to work with minimal external support.
Centrifuge Systems offers data visualization software with a specialty in link analysis (that is, finding relationships among entities such as members of a social network). It isn’t the only vendor in the field – a quick search brought up this list of link analysis systems, which itself is not complete. Centrifuge tells me they are unique in offering link analysis that doesn’t require client software (only a browser with Adobe Flash) and works without a predefined data model. I can't personally confirm this, but was intrigued enough by Centrifuge that its uniqueness is not a prime concern.
Like other link analysis systems, Centrifuge has been used primarily for criminal and intelligence investigations. However, it is currently looking for additional applications such as marketing analysis to understand relationships between customers, locations and products. Since it does conventional data visualization in addition to the link analysis, Centrifugre is at least a potential replacement for visualization tools like Tableau and TIBCO Spotfire.
I had a briefing from Centrifuge a few months ago and recently downloaded their free trial system to play with it a bit. Not surprisingly, it was harder to use by myself than when a salesman was showing it to me. But the basic interface made sense and I can see that with a bit of practice, this would be a pretty effective system for a business analyst even if they lacked deep technical skills.
Setting up a project involves uploading data to the server, connecting to it, and then dragging data elements into position as dimensions and measures. Links between data elements are also defined by dragging fields into place. Users can refine their views by creating filters, derived values and bundles to combine selected items. Results can then be displayed from multiple perspectives including tables, link maps, charts (bar, line, pie, etc.), geographic and bubble maps, timeline, geospatial and drill-down charts.
The dragging itself wasn't as smooth as a typical desktop application, but it was perfectly serviceable and pretty impressive for working within a browser. Charts rendered almost instantly using the small sample data set. A larger volume might slow things down, but the heavy lifting is done on the server, so the system should scale well if the server is adequate. Centrifuge says its largest installations involve thousands of users and many millions of database rows.
The most important feature of Centrifuge is probably its ability to upload and link pretty much any type of data. External connections use JDBC drivers, which support sources including spreadsheets, XML and live feeds as well as conventional databases. The latest release lets analysts add new data sources by themselves, letting them work quickly with minimal technical support.
The system also lets users extract a subset of data and analyze it independently, reducing the load on the server. They can share their work by publishing it to a server as a PDF or live asset available to others. Newly published assets can be listed in an RSS feed.
Centrifuge was founded in 2007 and has multiple government clients, plus a few in private industry. Pricing starts at $4,000 for a single user perpetual license plus 18% annual maintenance.
Centrifuge Systems offers data visualization software with a specialty in link analysis (that is, finding relationships among entities such as members of a social network). It isn’t the only vendor in the field – a quick search brought up this list of link analysis systems, which itself is not complete. Centrifuge tells me they are unique in offering link analysis that doesn’t require client software (only a browser with Adobe Flash) and works without a predefined data model. I can't personally confirm this, but was intrigued enough by Centrifuge that its uniqueness is not a prime concern.
Like other link analysis systems, Centrifuge has been used primarily for criminal and intelligence investigations. However, it is currently looking for additional applications such as marketing analysis to understand relationships between customers, locations and products. Since it does conventional data visualization in addition to the link analysis, Centrifugre is at least a potential replacement for visualization tools like Tableau and TIBCO Spotfire.
I had a briefing from Centrifuge a few months ago and recently downloaded their free trial system to play with it a bit. Not surprisingly, it was harder to use by myself than when a salesman was showing it to me. But the basic interface made sense and I can see that with a bit of practice, this would be a pretty effective system for a business analyst even if they lacked deep technical skills.
Setting up a project involves uploading data to the server, connecting to it, and then dragging data elements into position as dimensions and measures. Links between data elements are also defined by dragging fields into place. Users can refine their views by creating filters, derived values and bundles to combine selected items. Results can then be displayed from multiple perspectives including tables, link maps, charts (bar, line, pie, etc.), geographic and bubble maps, timeline, geospatial and drill-down charts.
The dragging itself wasn't as smooth as a typical desktop application, but it was perfectly serviceable and pretty impressive for working within a browser. Charts rendered almost instantly using the small sample data set. A larger volume might slow things down, but the heavy lifting is done on the server, so the system should scale well if the server is adequate. Centrifuge says its largest installations involve thousands of users and many millions of database rows.
The most important feature of Centrifuge is probably its ability to upload and link pretty much any type of data. External connections use JDBC drivers, which support sources including spreadsheets, XML and live feeds as well as conventional databases. The latest release lets analysts add new data sources by themselves, letting them work quickly with minimal technical support.
The system also lets users extract a subset of data and analyze it independently, reducing the load on the server. They can share their work by publishing it to a server as a PDF or live asset available to others. Newly published assets can be listed in an RSS feed.
Centrifuge was founded in 2007 and has multiple government clients, plus a few in private industry. Pricing starts at $4,000 for a single user perpetual license plus 18% annual maintenance.
Subscribe to:
Posts (Atom)


